4. File and Resource Management
- 4.1 The HECToR administration web site (SAFE)
- 4.2 Checking your CPU-time (kAU) quota
- 4.3 HECToR Filesystems
- 4.4 Disk quotas
- 4.4.1 Checking disk quotas
- 4.4.2 Quotas on the Lustre filesystem
- 4.4.3 Allocating quotas to specific groups and users
- 4.5 File permissions and security
- 4.6 Sharing data with other HECToR users
- 4.7 Sharing data between systems
- 4.8 File IO Performance Guidelines
- 4.9 Data archiving
- 4.10 Use of /tmp
- 4.11 Backup policies
4.1 The HECToR Administration Web Site (SAFE)
All users have a login and password on the HECToR Administration Web Site (also know as the 'SAFE'): http://www.hector.ac.uk/safe/. Once logged into this web site, users can find out much about their usage of the HECToR system, including:
- Machine status (also available via the normal website at http://www.hector.ac.uk/service/status/)
- Project details
- Detailed usage information including report generation
- Access to the Helpdesk
These features are largely self-documenting and are not described further here but more help can be found in the Frequently Asked Questions (FAQ).
4.2 Checking your CPU-time (kAU) quota
You can view these details by logging into the SAFE (http://www.hector.ac.uk/safe/). Scroll down to the panel marked "You are a member of the following project groups" and you will see how much time is left in a particular project.
You can also get the current kAU quota for your budgets on the service machine by using the budgets command. This will list all the budgets you are a member of and their current values. For example:
user@hector-xe6-3:~> budgets
=========================================
Budget Remaining kAUs
-----------------------------------------
d56 315.137
d78 3374.874
e05 No resources left
e05-surfin-smw 346.788
z01 2796.859
=========================================
4.3 HECToR Filesystems
There are currently two main filesystems on the HECToR service for user data, "home" and "work" (work is linked to esfs1 for NERC projects and esfs2 for non-NERC projects). Users have a separate quota for each filesystem.
The current filesystem layout on HECToR is summarised in the diagram below:
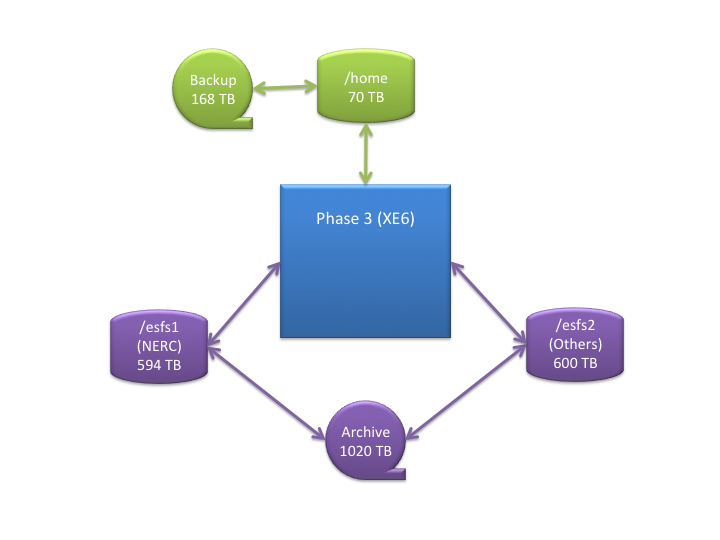
4.3.1 "home" filesystem
The home directory for each user is located at:
/home/[project code]/[group code]/[username]
where:
- [project code]
- is the code for your project (e.g., x01);
- [group code]
- is the code for your project group, if your project has groups, (e.g. x01-a) or the same as the project code, if not;
- [username]
- is your login name.
Each project is allocated a portion of the total storage available, and the project PI will be able to sub-divide this quota among the groups and users within the project. As is standard practice on UNIX and Linux systems, the environment variable $HOME is automatically set to point to your home directory.
The "home" filesystem is backed up, first to a second set of hard disks, and then to tape. This is the filesystem to use for critical files, such as source code, makefiles or other build scripts, binary libraries and executables obtained from third parties and small permanent datasets.
It should be noted that the "home" filesystem is not designed, and does not have the capacity, to act as a long term archive for large sets of results. Users must use the HECToR archive facility; transfer such data to systems at their own institutions; or suitable facilities elsewhere.
The "home" filesystem cannot be accessed from the compute nodes. Thus all files required for running a job on the compute nodes must be present on the "work" filesystem described below.
4.3.2 "work" filesystem
In a similar way to the "home" filesystem, the work directory for each user is located at:
/work/[project code]/[group code]/[username]
As for the "home" filesystem, each project will be allocated a portion of the total storage available, and the project PI (or Project Manager) will be able to sub-divide this quota among the groups and users within the project.
"work" is a network of high-performance Lustre filesystems, and hence includes some redundancy in case of hardware failure. There is no separate backup of data on either of the work filesystem, which means that in the event of a major hardware failure, or if a user accidently deletes essential data, it will not be possible to recover the lost files.
Note that work is not a scratch space - files created on work will remain after the completion of the batch job which created them. Users who desire temporary scratch files only for the duration of the batch job must manage this explicitly within their programs or batch scripts.
The "work" filesystem is the only filesystem can be accessed from the compute nodes. Thus the parallel executable (or executables) and all input data files must be present on the /work directory before the executable is run, and all output files generated during the execution of a program on the compute nodes must be written to the "work" filesystem.
Links from the "home" filesystem to directories or files on "work" are strongly discouraged. If links are used, executables and data files on "work" to be used by applications on the compute nodes (i.e. those executed via the aprun command) should be referenced directly on "work".
These files could be copied from home to work (or vice versa) within your batch job, before running the executable on the compute nodes using aprun.
Programs not run via aprun can access the "home" filesystem, as they run on the login nodes. It is not recommended that you do any significant file copying or executable runs on the login nodes during a batch job, as you will still be charged for the use of the compute node PEs you requested in your batch job for the duration of these commands whether or not you are actually running anything on the compute nodes. You can use the serial batch queues (which are free) for any extensive post-processing of file copying once the the job has finished.
It is highly recommended that users study the HECToR Good Practice Guide for IO for more information on how to read and write data efficiently within their applications.
- More information on running jobs on HECToR (including example job submission scripts)…
- HECToR Good Practice Guide for IO
4.3.2.1 ARCH and ARCH2 subdirectories
All users' /work space contains two subdirectories: one named "ARCH" and one named "ARCH2". These subdirectories are used for automatic archiving of user data during the nightly archiver run. Users should not place any working files in these directories as they could be removed durign the archiver run causing any running jobs to fail. The subdirectories should only be used for data that users wish to archive.
More information on the HECToR Archiver can be found in the archiver guide at:
4.4 Disk quotas
4.4.1 Checking disk quotas
User and group quota limits can be interrogated via the HECToR SAFE: http://www.hector.ac.uk/safe/.
In HECToR SAFE, the filesystems are labelled as follows:
- home - The "home" filesystem
- work (esfs1) - The "work" filesystem used by NERC projects
- work (esfs2) - The "work" filesystem used by non-NERC projects
4.4.2 Quotas on the Lustre filesystem
Each OST (Object storage target) implements its own quota. These quotas are increased and decreased automatically in 100Mb chunks as data is added and deleted to the OSTs. When the sum of the OST quotas equals the overall quota allocation then these OST quotas will no longer increase automatically and data writes may start to fail due to lack of quota space on the underlying OST. This can occur before the overall disk usage reaches the overall quota value because the remaining space may not be on the OST you are trying to write to.
On the "work" filesystems, the quota option to the Lustre lfs command can be used to get more detailed quota information than is available on the SAFE.
Important: when using lfs quota command it is important to specify filesystem as esfs1 (for NERC projects) or esfs2 (for non-NERC projects)
lfs quota -g [group code] /[filesystem]/[group code]
This command will produce detailed output on the overall disk usage and quota on /work as a whole, and on each of the Lustre OSTs within /work. Normally this detailed information is not required, so the following command may be more useful:
lfs quota /[filesystem]/[group code] | head -3
Information on disk usage for an individual user can found with the command:
lfs quota -u [username] /[filesystem]/[group code] | head -3
4.4.3 Allocating quotas to specific groups and users
This can be done by the project PI (or designated managers) through the SAFE. If you require further information please see the HECToR Administration for PI's and Project Managers FAQ.
4.5 File permissions and security
By default, each user is a member of the group with the same name as [group_code] in the /home and /work directory paths, e.g. x01-a. This allows the user to share files with only members of that group by setting the appropriate group file access permissions. As on other UNIX or Linux systems, a user may also be a member of other groups. The list of groups that a user is part of can be determined by running the groups command.
It is possible to make files accessible to all users in the group, by setting the "group" file access permissions appropriately. For security reasons it is recommended that you do not allow anyone else read or write access to important account information (e.g. $HOME/.ssh).
Default Unix file permissions can be specified by the umask command. The default umask value on HECToR is 22, which provides "group" and "other" read permissions for all files created, and "group" and "other" read and execute permissions for all directories created. This is highly undesirable, as it allows everyone else on the system to access (but at least not modify or delete) every file you create. Thus it is strongly recommended that users change this default umask behaviour, by adding the command umask 077 to their $HOME/.profile file. This umask setting only allows the user access to any file or directory created. The user can then selectively enable "group" and/or "other" access to particular files or directories if required.
4.6 Sharing data with other HECToR users
There is a directory for passing files to other HECToR users (for example support personnel) without having to use costly external transport. Files should be placed in either /esfs1/transfer (if your project is funded by NERC) or /esfs2/transfer (for all other users). This directory is readable by all and therefore users should be careful about what material is placed in there. Note that files in /esfsx/transfer still count against your normal work filesystem quotas. Users are advised to create their own subdirectory in /esfsx/transfer to help organise their files. Users should also delete files from /esfsx/transfer when they are no longer necessary.
4.7 Sharing data between systems
Many users will be generating data on HECToR and then analysing this data on other systems, e.g. at their host institutions. Users may also be using data files generated elsewhere as input for runs on HECToR. Therefore it is important to consider the compatibility of data files between HECToR and other systems. It is also important to consider compatibility issues for results files that are archived for future reference.
The two basic file formats in Fortran are:
4.7.1 ASCII (or formatted) files
These are the most portable, but can be extremely inefficient to read and write. There is also the problem that if the formatting is not done correctly, the data may not be output to full precision (or to the subsequently required precision), resulting in inaccurate results when the data is used. Another common problem with formatted files is FORMAT statements that fail to provide an adequate range to accommodate future requirements, e.g. if we wish to output the total number of processors, NPROC, used by the application, the statement:
WRITE (*,'I3') NPROC
will not work correctly if NPROC is greater than 999.
4.7.2 Binary (or unformatted) files
These are much faster to read and write, especially if an entire array is read or written with a single READ or WRITE statement. However the files produced may not be readable on other systems. As the Cray is based upon Opteron processors and the Linux OS, it may be easier to share binary data files with other such systems, such as individual PCs or local Linux clusters, than it was from earlier Cray systems. However, as the Opteron is a little-endian processor, binary data files produced on HECToR will not be directly compatible with big-endian systems such as the IBM POWER5. Tools and compiler options are available in many Fortran compilers to assist with accessing big-endian files on the Cray. These include:
- PGI compiler: -byteswapio (or -Mbyteswapio) compiler option.
- GNU compiler: -fconvert=swap compiler option. This compiler option often needs to be used together with a second option -frecord-marker, which specifies the length of record marker (extra bytes inserted before or after the actual data in the binary file) for unformatted files generated on a particular system. To read a binary file generated by a big-endian system on HECToR, use -fconvert=swap -frecord-marker=4. Please note that due to the same 'length of record marker' reason, the unformatted files generated by GNU and other compilers on HECToR are not compatible. In fact, the same WRITE statements would result in slightly larger files with GNU compiler. Therefore it is recommended to use the same compiler for your simulations and related pre- and post-processing jobs.
Finally, there are performance penalties associated with the endian-conversion process. In our test, when reading a 250MB unformatted file generated by a POWER 5 machine (in comparison to the same file generated locally on HECToR), the PGI, PathScale and GNU code are 23%, 91% and 29% slower, respectively. It is therefore beneficial to convert your binary files permanently for HECToR, unless you have good reasons not to do so.
Other options for file formats include:
- Direct access files
- Fortran unformatted files with specified record lengths. These may be more portable between different systems than ordinary (i.e. sequential IO) unformatted files, with significantly better performance than formatted (or ASCII) files. The "endian" issue will, however, still be a potential problem.
- Portable data formats
- These machine-independent formats for representing scientific data are specifically designed to enable the same data files to be used on a wide variety of different hardware and operating systems. The most common formats are:
- It is important to note that these portable data formats are evolving standards, so make sure you are aware of which version of the standard/software you are using, and keep up-to-date with any backward-compatibility implications of each new release.
4.8 File IO Performance Guidelines
Here are some general guidelines
- Whichever data formats you choose, it is vital that you test that you can access your data correctly on all the different systems where it is required. This testing should be done as early as possible in the software development or porting process (i.e. before you generate lots of data from expensive production runs), and should be repeated with every major software upgrade.
- Document the file formats and metadata of your important data files very carefully. The best documentation will include a copy of the relevant I/O subroutines from your code. Of course, this documentation must be kept up-to-date with any code modifications.
- Use binary (or unformatted) format for files that will only be used on the Cray system, e.g. for checkpointing files. This will give the best performance. Binary files may also be suitable for larger output data files, if they can be read correctly on other systems.
- Most codes will produce some human-readable (i.e. ASCII) files to provide some information on the progress and correctness of the calculation. Plan ahead when choosing format statements to allow for future code usage, e.g. larger problem sizes and processor counts.
- If the data you generate is widely shared within a large community, or if it must be archived for future reference, invest the time and effort to standardise on a suitable portable data format, such as netCDF or HDF.
4.9 Data archiving
The HECToR system includes a long term archive storage facility. You can find out more in the HECToR Archiver User Guide at:
http://www.hector.ac.uk/support/documentation/guides/archiver/
If you require access to the archiver please contact the HECToR Helpdesk:
http://www.hector.ac.uk/support/helpdesk/
The data archiving requirements may vary considerably between different HECToR user communities, but some common points to consider are:
- Clear records of what the data represents are vital. Careful choice of filenames and including metadata within the data files can assist in this process.
- Using a tar file to combine multiple data files associated with a single calculation into a single file may not only improve the performance of downloads from HECToR, but will also preserve the the userid and timestamp information of when the data files were created.
- Do not separate media from device. For example, having your data archived on a tape (particularly if this is done by someone else on your behalf) is not much use if in say five years time, when you need access to the data, you cannot get access to a compatible tape drive. Also be aware of the shelf life of media such as tapes, DVDs, etc.
- Be aware of the limits on the redundancy and fault tolerance of your storage system. For example, many RAID storage systems include error correcting functionality, where single-bit errors in the data files can be fixed automatically. However, this may only apply when files are read or written - if files are not accessed for some time, a number of random single-bit errors may accumulate, resulting in corrupted or unreadable data.
- When changing the formats or file structure of any I/O in your software (both the main production codes and any pre- or post-processing or visualisation codes), consider the impact of these changes on your ability to access old archived data files.
4.10 Use of /tmp
The /tmp directory is not available to applications on the compute nodes of the HECToR machine. The /tmp directory on compute nodes is a memory resident file system; its use to store temporary files could, therefore, seriously affect application performance on those nodes. Temporary files created as part of an application run should be written to somewhere under your own directory on the "work" filesystem.
Note that some Fortran codes include file OPEN statements specifying STATUS='SCRATCH'. Such codes, if compiled with the default PGI Compiler or the GNU Fortran compiler, will attempt to use /tmp and fail. The solution is to set an environment variable to a directory in your "work" space. For PGI this environment variable is TMPDIR and for GNU it is GFORTRAN_TMPDIR. In your batch script you should have e.g.:
export TMPDIR=/work/[project]/[group]/[username]/tmp
or:
export GFORTRAN_TMPDIR=/work/[project]/[group]/[username]/tmp
(replacing [project], [group] and [username] with your project, group and username). You should include the relevant line in your submission script and make sure that the specified directory exists before running the job.
On HECToR login nodes, where full SUSE Linux is installed, /tmp is a regular temporary filespace used, for example, by compilers and tools. It should be noted that /tmp is regularly purged and should not be used by users for the storing of any data.
4.11 Backup policies
The policy describing the procedures which are used to backup the HECToR systems is given in Policies section of the HECToR Website.
The general advice is to make regular transfers of material from the HECToR systems to a local machine and manage your backups from there.
3. Connecting to HECToR | Contents | 5. The Modules Environment
")