
Good Practice Guide
IO
Contents
Performing IO properly becomes as important as having
efficient numerical algorithms when running large-scale computations on supercomputers.
A challenge facing programmers is to understand the capability
of the system (including hardware features) in order to apply suitable IO
techniques in applications. For example, most operating systems use buffers
to temporarily store data to be read from or written to
disk. This decouples the interaction between the application and the IO
device, which allows the read/write operations to be optimized, and as a consequence
it is often more efficient to read/write large chunks of data.
Another example is that most supercomputers (including HECToR) have parallel filesystems, which
means that it is possible to write to files in parallel over multiple physical disks, a technique called
striping. In striping your data it is typically preferable to work with a small number
of large files, rather than a large number of small files.
This guide covers some good practices regarding
input/output from/to disk. The aim is to improve awareness of basic
serial and parallel IO performance issues on HECToR. In the following sections,
a variety of practical tips are introduced to help you use HECToR's
IO system effectively, so that you can manage large data sets properly.
User account sharing is not allowed on HECToR. One recommended way to
share your files with your colleagues and collaborators is to use the /esfs2/transfer
directory, which is globally readable by all users.
Secure-shell based programs (such as 'scp') are often the preferred tools to transfer data to and from HECToR. If you need to move a large amount of data
then bbFTP is often more efficient. Before moving large amount of data (in particular ASCII data), it may be beneficial to
archive and compress first using utilities such as 'tar', 'gzip' and 'bzip2'. Please remember to use
the serial queue for time-consuming jobs to avoid overburdening the login nodes.
- ASCII format: This human-readable format is very portable
and suitable for sharing small amount of data (such as program parameters).
- Binary format: Binary files can be read or written more efficiently by computers
but are less portable. One major issue is the endianness
of data. When sharing data between HECToR (little-endian) and
big-endian computers (such as most IBM systems), binary data is not
compatible. Compilers may provide flags to
convert the data format at runtime: -Mbyteswapio for PGI,
-fconvert=swap for GNU, and -h byteswapio for Cray CCE compiler.
- Portable data formats: If data portability is essential to your work,
consider using netCDF or HDF,
which are specifically designed data formats for
storing scientific data in machine-independent manners. These file
formats also support the concept of 'metadata' - data describing the
data itself which may be very helpful when sharing data among
collaborators. Both packages are available on HECToR as modules.
Please note that data generated by your applications on the /work file system is not backed up. Although the likelihood of losing data is quite low, it is a good practice to regularly
transfer important data to your local storage or use the Research Data Facility.
Note that some of the tips in this section can be applied to the majority of computer systems, from desktops to supercomputers.
On HECToR, standard output is by default written to a shared system location.
Therefore writing large amount of data to it may affect other users. Consider using it for debugging only and redirecting
standard output from your job script to a file, e.g. aprun [parameters] executable > screen_output
The opening, and closing, of files involves a
considerable system overhead. Here are a few tips:
- Do not open and close files more than is necessary and do not have too many files open at one time.
- Ensure that files are opened in the correct mode (for example
'read-only').
This allows the system to optimise the IO operations. (This is also good
practice and prevents any unfortunate accidents where applications
write to files that should not be modified.)
- The FLUSH operation (forcing system buffer to be written to
disks) also involves big overhead and should be used only when
necessary.
- If possible, buffer data in memory to avoid frequent file operations.
As a practical example, an application might write a small amount of
information regularly to a log file as computation progresses and write
a large amount of scientific data to a data file occasionally. Clearly
the former file can remain open and the latter should be opened and
closed as appropriate.
- In general, read/write data in large blocks to get the best performance.
- In particular, in Fortran, write a whole array using a single WRITE statement, rather than
writing its elements individually. This can often be much faster and result in smaller binary files.
- Design your applications to use fewer but larger files. The HECToR
LUSTRE filesystem (and indeed most file systems used by supercomputers)
prefers to handle a small number of large files.
In some cases it may be desirable to move through a
direct-access
file reading only a subset of the data, in particular when data is
arranged in fixed-length
records. Records may be written to a direct-access file in any order.
Careful consideration should be given to the choice of such order to
minimise the file pointer movements.
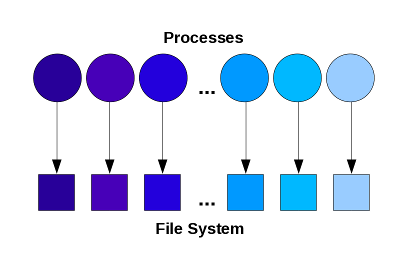
This is perhaps one of the simplest ways to write
in parallel. Each process writes its own file, with different file-names
generated using unique IDs (such as the MPI ranks).
Advantages
Disadvantages
- Opening a large number of files may overwhelm the file system.
- Lots of small files to manage in post-processing.
- Difficult to read data back when using a different number of processes.
The best use of this approach is when only a small
number of files are involved
and the files are only going to be used by the parallel application on
the same system (for example restart files). It can be highly effective
for systems with local disks attached to each node.
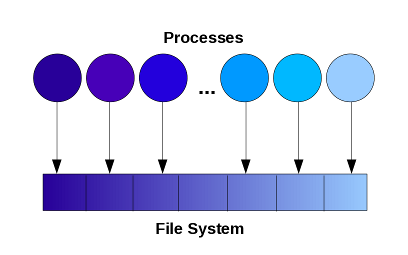
In this approach, the user application controls
where in the overall file structure each process will write its data.
This can be achieved using direct access file or through a high-level
library such as MPI-IO.
Advantages
- Minimal file system overhead.
Disadvantages
- Application needs to explicitly manage the partitioning of global data and avoid conflict - more difficult programming.
This approach works well with a small number of processes but may fail to scale to thousands.
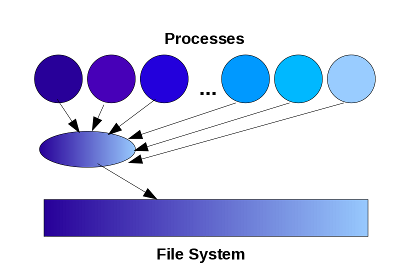
This is the model in which parallel programs define a
single 'master process' to collect data from all other processes for
IO. This can be implemented easily using MPI message passing.
Advantages
- Producing identical file formats to serial code - easy post-processing.
Disadvantages
- Many-to-one communication pattern hard to scale.
- Imbalanced workload.
- Limited by the memory available on the master process.
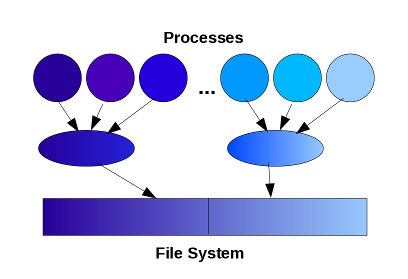
This is an extension of the single writer model where many
processes act as local master processes and write data sent by a group of processes, either to separate files or
to different parts of a single file.
Advantages
- Improved communication pattern and memory usage situation.
- More scalable than other IO models.
Disadvantages
- Much more difficult to program.
- Still some workload imbalance.
It may be possible to map the number of writers to the hardware configurations
(number and topology of the physical disks) to achieve best possible performance. However,
this is a very advanced technique that requires knowledge of the LUSTRE File System
and its optimisations. For large-scale
parallel applications, to further address the load balancing issue, it may be possible
to introduce dedicated IO processes which receive data from the computation processes and
perform IO separately when computations are in progress.
MPI-IO is a programming interface defined in the
MPI 2 standard
for performing file read and write operations in parallel applications.
This section will very briefly go through the major features of MPI-IO
but it does not intend to be a tutorial. Here is a list of resources for
further information:
- High Performance:
MPI-IO is designed to be efficient.
For example, it defines collective operations so that major IO
operations can be implemented and optimised at the library level. A
second example is its ability to overlap IO and computations through
non-blocking operations.
- User Friendly:
The MPI-IO programming interface
looks very similar to other parts of the MPI standard, which you are
likely to be more familiar with, so MPI users can pick it up easily. For
example, MPI-IO write routines are similar to MPI send routines and
MPI-IO read routines are similar to MPI receive routines; for
non-blocking operations, the same 'waiting' procedure applies.
- Portable:
MPI-IO provides a standard interface for
parallel I/O. It is available on all major computing platforms as long
as an MPI2 library is available. The library also provides means for
ensuring file interoperability among different systems.
Finally, a real-world case-study, taken from a dCSE project, is given to demonstrate the level of
improvement that can be achieved when proper IO techniques are employed.
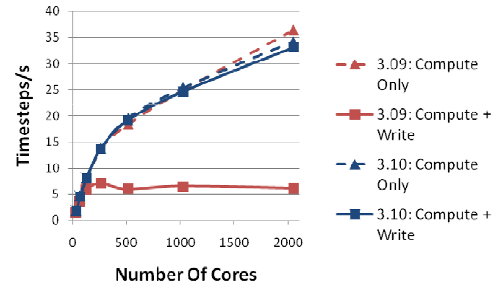
The following figure shows the performance of the molecular dynamics
application DL_POLY_3. In version 3.09, the code only scales up to about
128 cores due to the degraded IO performance at higher core counts. In
version 3.10, while the computational algorithms of the code remain
unchanged, significant performance improvement has been obtained by
introducing 'multiple writer' model and rearranging data to allow larger
IO transactions, making the code scale to thousands of cores.
More information about this dCSE project can be found here: IO in DL_POLY_3.
Fri Aug 2 09:42:54 BST 2013