DBCSR (Distributed Block Compressed Sparse Row) is a library embedded within CP2K which had been developed to provide a storage format and multipication operation for the sparse block-structured matrices used within CP2K. Many of the large matrices stored in CP2K (density matrix, overlap matrix, Kohn-Sham matrix etc.) are naturally sparse due to the localisation of the Gaussian basis set in space. The block structure arises from the fact that each atom may be represented by a number of basis functions. Thus for a system with N atoms, typical matrices would have N rows (or columns) of blocks, where each block itself comprises multiple rows (or columns) e.g. 1 for Hydrogen with a minimal basis set (SZV-GTH-MOLOPT), or 13 for Oxygen with a larger basis set (DZV-GTH-MOLOPT). Thus the entire matrix is composed of rows and columns of small dense blocks of varying size. Blocks are addressed using a CSR storage format where an indivdual block can be accessed via a pointer to the start of it's row, plus an offset into the row for that block. The matrices are distributed across MPI processes in a 2D grid.
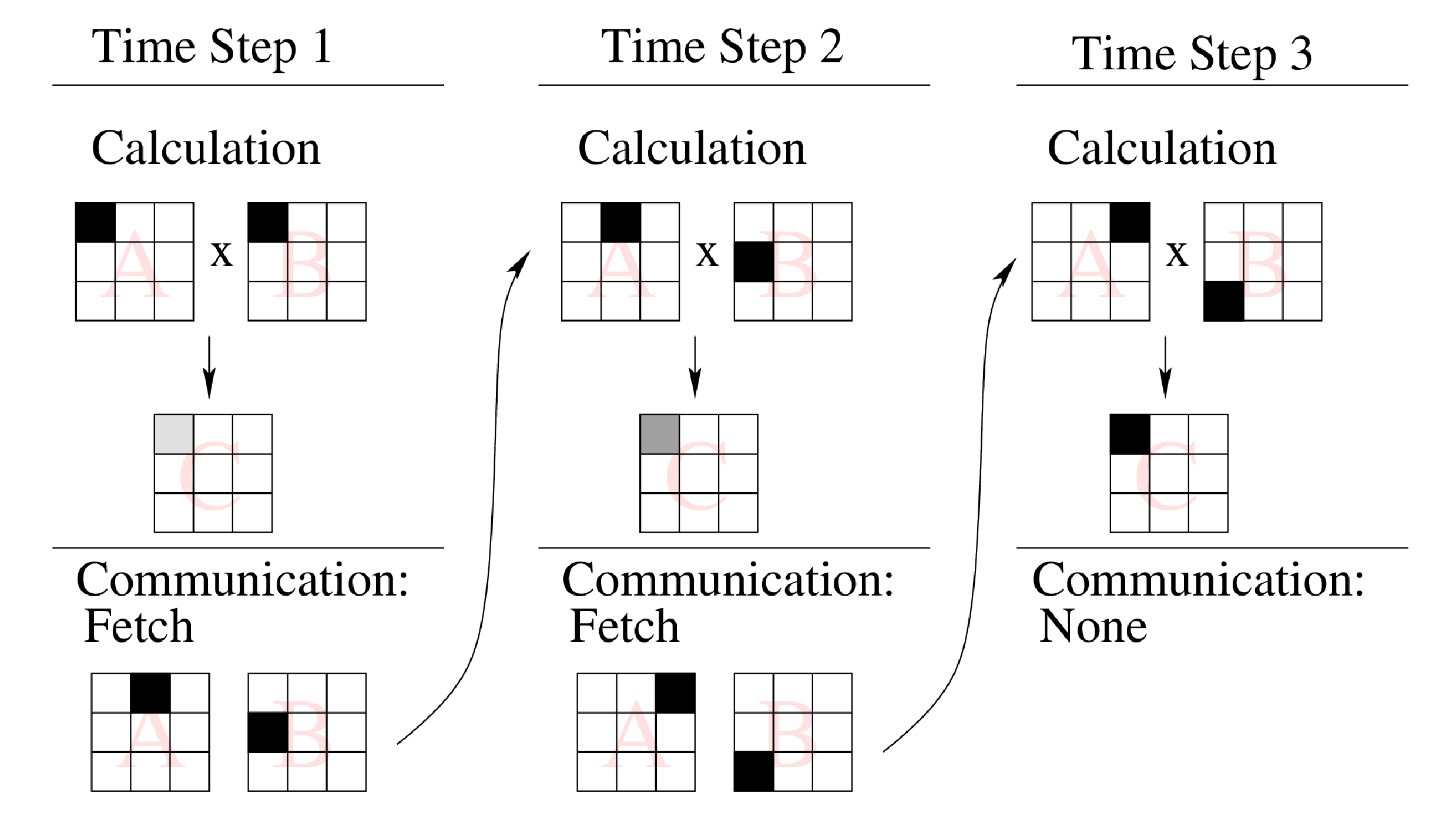
Matrix multiplication is performed using Cannon's algorithm[8]. Briefly, to perform the multiplication C = A*B where the matrices are distributed on a square grid of P processes, there are ![]() steps in the algorithm. At each step the local data area is multiplied and acculumated into the result matrix, then row-wise and column-wise shifts (for matrix A and B respectively) are performed using non-blocking MPI. This operation is illustrated in figure 3.
steps in the algorithm. At each step the local data area is multiplied and acculumated into the result matrix, then row-wise and column-wise shifts (for matrix A and B respectively) are performed using non-blocking MPI. This operation is illustrated in figure 3.
The communication is performed using double-buffering - with calc and comm buffers to hold current and next matrix data and index - as illustrated by the following pseudocode:
[frame=single]
do i=1,nsteps
call mpi_waitall() - ensures communication from previous iteration
is complete (new data has arrived in current calc buffer,
comm buffer data has been sent)
post mpi_irecv() and mpi_isend() for column and row shifts - data is
sent from the current calc buffer, and received into the comm buffer
perform C += A x B on current calc buffers
comm and calc buffers are (pointer) swapped for next iteration
end do
In order to take advantage of OpenMP, DBCSR decomposes the rows of blocks of a matrix over the available team of threads. Load balancing is achieved by assigning rows to threads so that the total number of blocks per thread is approximately equal (since in a sparse matrix, each row may now have the same number of non-zero blocks). Matrix rows are then reordered so each thread's rows are contiguous in memory.