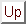


Next: MPI data exchange
Up: Node-local data multiply
Previous: SMM
Contents
Recall that DBCSR matrices are decomposed by rows, which each row being `owned' by a specific OpenMP thread. The current load balancing strategy (rows are assigned weighted by the block size of each row) results in some load imbalance since it does not take account of the sparsity of each row.
When investigating how to improve the load balance it was discovered that thread 0 was consistently taking longer than the other threads by up to 20% (even for artificial inputs which are perfectly load balanced). Careful inspection of the code revelead this was due to timing routines called by every thread which contained !$omp master directives. These were removed from the recursive part of the multiplication, since timing detail at this level is not of interest to users, and can be obtained via profiling if necessary.
To achieve a better load balance using the total number of blocks in a (distributed row) as the criteria for assigning rows to threads was investigated. This achieves a good overall load balance of FLOPs for matrix multiplication (see table 1). However, due to the multiple steps involved in the Cannon's algorithm multiplication, when DBCSR is used for more than one MPI process, each local multipication is still not guaranteed to be load balanced, and in fact significant load imbalance is observed, leading to poor scaling of the multipication with larger thread counts. In addition, calculating the number of blocks per row requires an MPI_Allreduce per processor row which incurs some synchronisation cost. As a result, this load balancing method was not added to CVS.
Table 1:
Comparison of load balancing strategies
| |
Row sizes only(CVS) |
Row block counts |
| Thread |
Blocks |
Time(s) |
Blocks |
Time(s) |
| 0 |
25806281 |
895.52 |
23249480 |
921.14 |
| 1 |
23278623 |
868.15 |
23271941 |
813.60 |
| 2 |
21799888 |
758.59 |
23284712 |
788.97 |
| 3 |
26823318 |
1050.02 |
23261575 |
896.97 |
| 4 |
15986481 |
629.71 |
23254617 |
1003.18 |
| 5 |
25902624 |
995.68 |
23274890 |
813.44 |
|
Since this load imbalance is intrinsic to the idea of having threads `own' fixed rows of the matrix, two further modifications to the threaded multiplication were proposed to allow threads to share access to the result (C) matrix in more flexible manner:
- 1.
- Using OpenMP 3 tasks, create a task for each leaf of the recursive multipication, ensuring that the recursion terminates such that there are many more tasks than threads. Then in each task, take a lock on the corresponding area of the C matrix to protect against concurrent update from another thread. Testing in the standalone code showed that generating and executing the tasks did not give too much overhead, especially when the number of thread is small i.e. within a single NUMA region so that memory access is not an issue (see figure 6, showing performance of the standalone test code). However, the addition of the locking overhead was roughly equivalent to the cost of the load imbalance, so this was not integrated into the main code.
Figure 6:
Performance of OpenMP tasked version against ideal SMM on 24-core XE6 (CSCS)
|
|
- 2.
- In the process of adapting DBCSR to use GPUs (HP2C-funded work by Urban Borstnik, Univ. Zurich) an extra layer of indirection was added - queues of the multiplication parameter stacks. It was proposed that as the matrices are recusively divided, a queue is created for every resulting sub-matrix. Each thread fills the stacks corresponding to its parts of the matrix, following the current thread distribution, and puts them in the appropriate queue. The threads then process queues independently (preferentially by the thread that filled the queue), but with the possibility that if a thread has no work left in its queues it can start processing queues filled by other threads. This avoids the overhead of locking since only a single queue every writes to a given area of the C matrix, and load balancing is achieved by dynamic `work-stealing'. This method also avoids the current overhead of merging each threads private `work matrix' since all threads could now write directly to a shared data area. While this idea seems in principle to solve all the current load balance problems, it would very complex to implement and so was not attempted in the scope of this project
Next: MPI data exchange
Up: Node-local data multiply
Previous: SMM
Contents
Iain Bethune
2012-01-17