Craypat profiling indicated that the majority of time spent in MPI during the multiplication loop was in MPI_Waitall, with quite a large imbalance (some processes spending up to 6 times longer than the fastest), although the amount of data sent from one process to another is well balanced, as is the computation performed by each process between communications. Even though the existing double-buffering allows computation to take place while communication for the next iteration is ongoing, the MPI_Isend and MPI_Irecv calls are posted at the same time. If the recieves could be pre-posted far enough in advance it was hoped this might reduce the time spend in MPI_Waitall by reducing the need for additional data copies for unexpected messages (arriving before the corresponding recieve is posted). This was done by posting the recieve a whole iteration earlier than the corresponding send (and two whole iterations before it was due to complete). Unfortunately, this did not reduce the time spent it MPI_Waitall as expected.
Another experiment to determine if the wait time was due to message latency (i.e. genuinely waiting because the message had not arrived from the remote process) was carried out. Here the local multiplication step was made arbitrarily long by sleeping for several seconds after actually carriying out the multiplication. This also did not affect the amount of time in MPI_Waitall, so it was determined that the cost of the waitall must be due to work that could only be done when MPI was called (i.e. requiring the MPI progress engine), rather than asynchronous DMAs or similar, although exactly what was occurring is not clear.
Given that this cost is fixed, we implemented a scheme whereby during the multiplication, the master thread would periodically poll MPI by making MPI_Testany calls. This has two advantages - firstly at least while the MPI processing was ongoing, other threads were doing useful work (rather than having the other N-1 threads idle during the Waitall). Secondly, since each local multiplication may be be somewhat load imbalanced, if thread 0 is underloaded then the MPI_Testany calls become essentially free as they simply take up some of the slack time that would be spent waiting for other thread to complete. To account for the case where the polling of MPI takes significantly longer than the available slack time, it is possible for the user to manually underload the master thread by a specified amount. This behaviour is controlled by two new variables in the input file (in the GLOBAL / DBCSR section):
During multiplication, use a thread to periodically poll MPI to progress outstanding message completions. This optional keyword cannot be repeated and it expects precisely one logical. Default value: .TRUE.
If a communications thread is used, specify how much multiplication workload (%) the thread should perform in addition to communication tasks This optional keyword cannot be repeated and it expects precisely one integer. Default value: 100
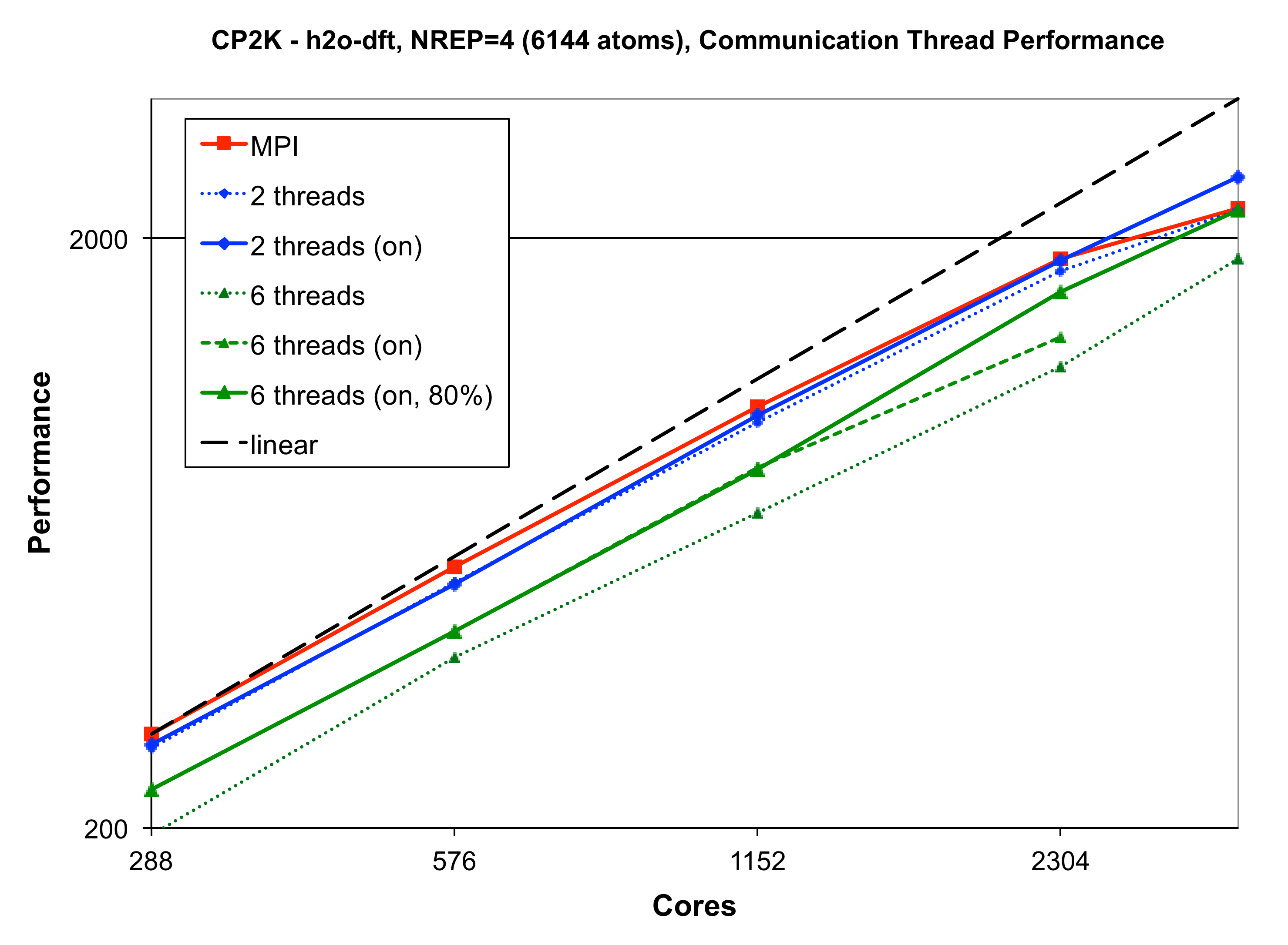
The performance of CP2K with and without the comm thread enabled is shown in figure 7. The benchmark used here is a 6144 atom calculation of liquid water using the new linear-scaling DFT[6] implementation, which is strongly dominated by DBCSR operations as it performs SCF via iterations on the density matrix. Here we see that using a Communications thread can give up to a 13% improvement when used with two threads up to 20% wthen using six threads, even on relatively modest numbers of processors. At 2304 cores and above, underloading the comm thread to 80% is also shown to give an improvement over the default settings.
 |