It should be noted that in contrast to prior CP2K dCSE projects where optimisation was carried out with the support of the development team, but on fairly independent sections of the code, in this project the optimisation was carried out at the same time as the DBCSR[5] library was under active development. It is therefore difficult to seperate the benefits of the dCSE-funded work from the wider development of DBCSR, although in the following section of the report we will detail exactly what work was carried out and show performance results for all changes made.
 |
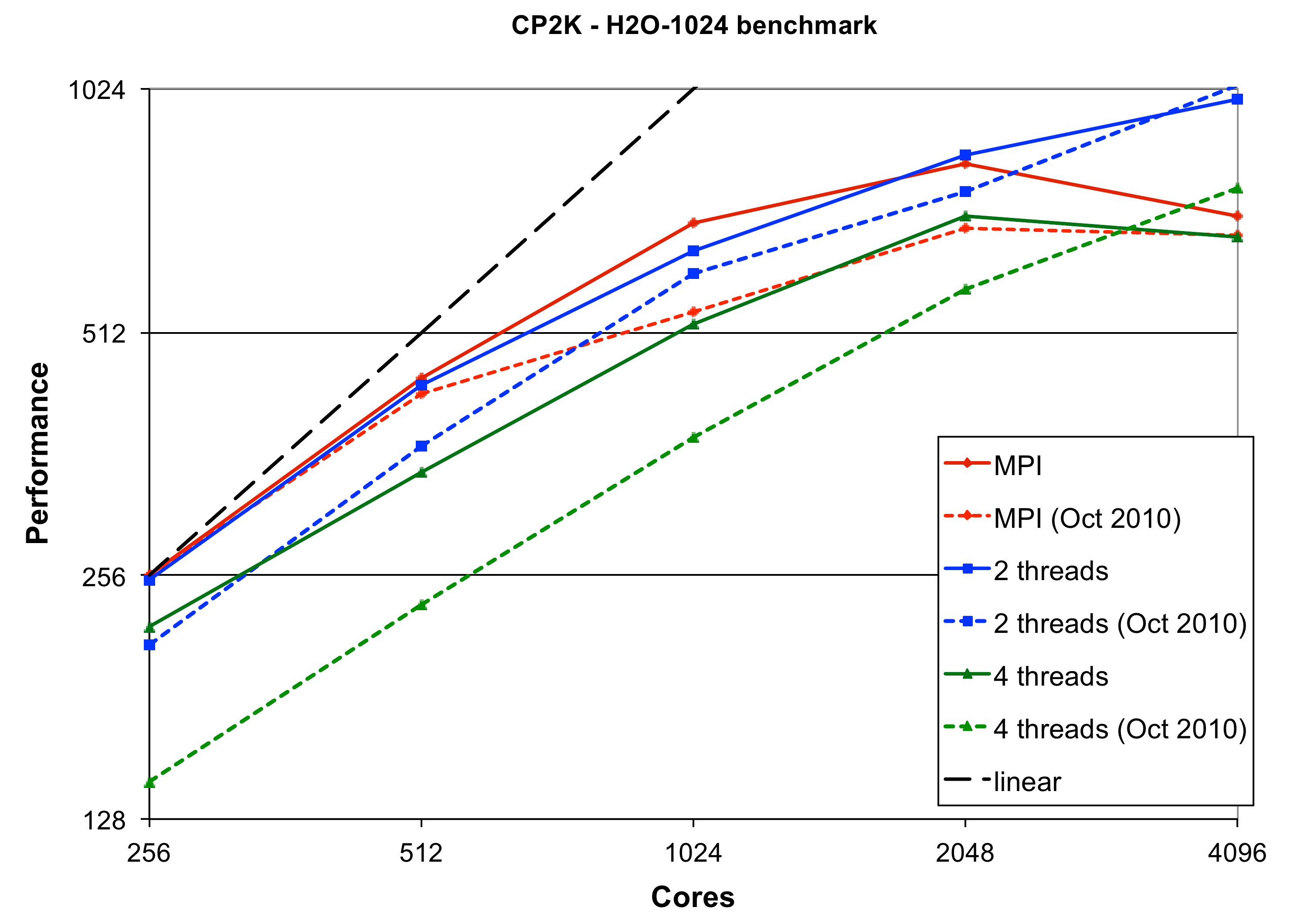 |
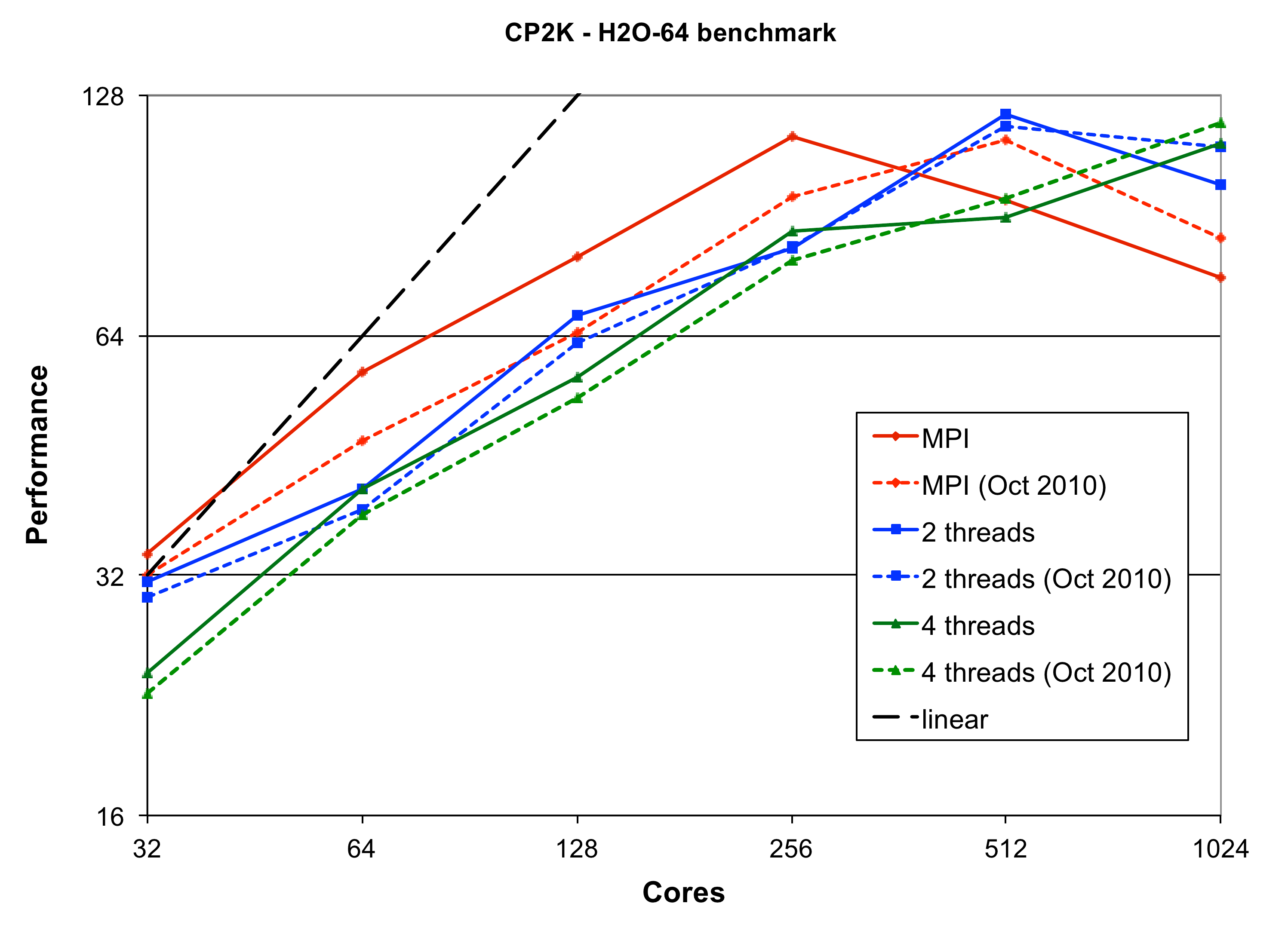
To quantify the performance of the code, we compare two versions of CP2K on the most recent HECToR hardware (Phase 3, XE6, 32 cores per node) - CP2K 2.1.390 (1st Oct 2010), and CP2K 2.3.r12105 (22nd Dec 2011). The benchmark inputs H2O-64 and H2O-1024 are molecular dynamics runs using cubic cells of 64 and 1024 water molecules respectively. These represent typical and fairly large systems that might be studied currently with CP2K. Both use the GTH Basis Set[9] (TZV2P) and the PBE[10] and PADE exchange-correlation functionals respectively. The performance of both versions of CP2K, for varying numbers of threads per MPI process is shown in figures 1 and 2.
Several performance objectives were stated in the project proposal:
For the H2O-64 benchmark on 32 cores is mostly compute dominated (approximately 15% of the runtime is spent in communication). Here we see that the mixed-mode code still lags a little way behind pure MPI (9% for 2 threads, 42% for 4 threads). However, only about 40% of the runtime is spent in DBCSR, so there are still significant other areas of the code that do not have as good threaded performance.
In the communication-dominated regime (e.g. on 512 cores, 39% is communication), we see that using 2 threads per MPI process gives a speedup of 22% over pure MPI.
The larger H2O-1024 benchmark spends about 70% of its runtime in DBCSR. Here the goal of achieving equal performance between mixed-mode and pure MPI has been achieved for compute-dominated runs (on 256 cores, 12% is communication). In particular, compared to the Oct 2010 version of the code, the performance with 2 threads per process has been increased by 18% and for 4 threads per process by 35%.
Similarly to H2O-64, we see that as the total number of cores is increased and communication begins to dominate, the mixed-mode code begins to perform better (e.g. an improvement of 29% over pure MPI on 4096 cores).
Extensive testing of similar benchmark inputs ranging from 32 to 2048 water molecules has been performed by Joost VandeVondele on the Cray XE6 `Monte Rosa' system at CSCS. Analysis of these results showed that the absolute fastest time to solution for all problem sizes could be achieved using 2 OpenMP threads per process.
The H2O-64 results on 32 cores show an improvement over the Oct 2010 code of 7% (pure MPI). For H2O-1024 there is little change in the peformance for pure MPI, but as noted above large improvements have been made for the mixed-mode code.
It is difficult to draw general conclusions about performance in the communication-bound regime from the H2O-64 data. The best case performance (2 threads per process, 512 total cores) has been increased by 4%, but in other cases the mixed-mode code performs slightly worse that before. For H2O-1024 at the highest cores count tested (4096) the newer code performs 6% faster than the Oct 2010 version for pure MPI, but 4% worse with 2 threads per process.