
Preparing for HECToR Phase II (Quad Core)
Contents
HECToR is due to enter its next phase of operation in summer 2009, which means
that some of the hardware will be updated.
In particular, the current dual core AMD Opteron processors in the Cray
XT41 part of the
service will be replaced with quad core AMD Opteron processors.
This important change will double the number of cores available and upgrade
HECToR's theoretical peak performance from around 60TF to over 200TF and also
increase the total memory footprint from 35TB to 45TB.
The switch to the quad core processors is not simply a doubling of cores however
because the new processors have key architectural differences
which will have performance implications for users of the system.
This guide explains what will happen to HECToR during the transitional period,
outlines what kinds of codes should benefit from the changes, advises what you can do to
prepare for the upgrade and gives some details about the key architectural differences to the system.
1: The Cray X2 part of the service will remain unchanged.
The Cray XT4 part of HECToR currently has 5,664 dual core processors (i.e.
11,328 cores) each with 6GB of memory (3GB per core).
The upgrade will take place in two parts. During the first part half the current number of
dual core processors will be available to users (2,832 processors;
5,664 cores).
During the second part the same number of newly installed quad core processors will
be available (11,328 cores).
Once the upgrade is complete the machine will consist of 5,664 quad
core processors each with 8GB of memory, or 22,656 cores with 2GB each.
Note that the dual and quad core processors will never be functional concurrently,
so there should be no confusion regarding which type of processor your jobs will
be running on during the upgrade.
Who will benefit?
The section Quad Core Architecture below highlights the key changes that will
have an effect on performance.
Phase 2 brings double the number of cores to the system and will therefore favour codes that scale
well, make effective use of the new cache hierarchy and carry out core computational work as packed
SSE instructions.
Codes that do not have these characteristics will require some work in order to get
the most out of the new system and are likely to perform poorly if performance issues are not addressed.
In particular, the per-core memory statistics show that there will be a decrease in
memory size and bandwidth, which means that memory-bound codes will not benefit from the
upgrade.
The new quad core system will be less forgiving of codes that perform adequately on the current system.
For example, codes that scale only to the point that enough processes are used to distribute 3GB of
memory per core in phase 1 are likely to perform poorly when scaled to higher numbers of processes
in order to distribute 2GB of memory per core in phase 2.
Set aside some time to benchmark your code on the new system and compare the results with those
from the current dual core setup.
The upgrade is also a good time to check that you are using libraries wherever possible. This is important
in order to make your life as a developer easier and take advantage of the dedicated
effort put into solving a specific problem efficiently. Make sure you are using the most up to date
versions.
For example, FFTW 3 is designed to make use of packed SSE instructions, whereas FFTW 2 is not,
so it may be worth the effort to switch to the new interface. Remember too that vendor-tuned libraries
(ACML and libsci) are likely to provide the most efficient routines in most cases.
The most important aspect of achieving high performance with the quad core processors is utilising
packed SSE instructions, and it is the compiler's job to generate these for you. In order to make
sure that packed SSE instructions are being used for the key computational regions of your code use the compiler options
-Minfo for the PGI compiler (-Mneginfo to see what is not vectorized, which may be more important)
and -LNO:simd_verbose=ON for the Pathscale compiler.
See the Good Practice Guide for Serial Code Optimisation for information about
compiler optimisation flags.
If compiler optimisation fails to improve performance significantly, the next step is code optimisation.
Use CrayPAT to profile your code and understand the performance
bottlenecks. It will be more important to use techniques for effective cache management
such as loop reordering, cache blocking and prefetching. Also, remember that single precision floating point
operations can be carried out at twice the rate of those in double precision, so use double precision
reals only where required. See the Good Practice Guide for Serial Code Optimisation
for more information about code optimisation.
Hybrid MPI-OpenMP programming may be an option to consider if each process in your code currently
contains significant computational sections (e.g. loops) that may be more finely parallelised.
Hybrid codes make use of MPI for inter-processor communication and OpenMP for intra-processor communication,
so that each of the four cores within a processor uses multithreaded SMP parallelism. The advantage of
this approach is that the
4 threads within a processor can share much of the same data structures, thus providing more scope for
cache optimisation and minimises off-chip traffic both to memory and to the Seastar interconnect for IO and inter
process communication.
Since the number of cores will double in phase 2, it is even more important to make sure your code scales
well. See the Good Practice Guide for Parallel Optimisation for an in-depth discussion of Amdahl's
law and how to improve scaling. The need to scale to higher numbers of processes means that if your code
performs well at the node level, the limiting factor will become the sequential activities such as IO.
Such activities may have had a tolerable impact on performance in the past, but in order to scale further, phase 2 may be the
time to parallelise these regions too. For the specific case of IO, see the parallel IO section of the
Good Practice Guide for IO.
Quad Core Architecture
The diagram in Figure 1 highlights three key architectural differences between the current
dual core and phase 2 quad core processors:
- Each of the cores in the quad core processor has a slower clock speed compared to the
dual core processor.
- There is a different cache hierarchy, with smaller L2 caches and a new shared L3 cache.
- Memory is increased from 6GB to 8GB per processor with an increased transaction frequency.
We will look at each of these differences in turn.
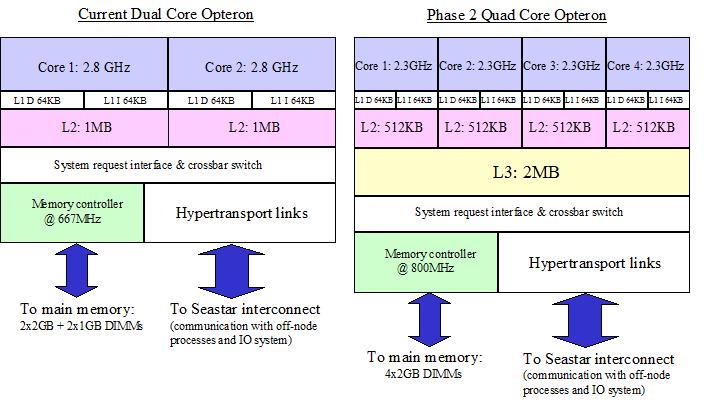
Figure 1: The architectural differences between the current dual
core and phase 2 quad core processors.
1. Slower clock rate
Although the new quad core processors have a slower clock speed each core is able to process double
the number of floating point operations per cycle compared to the dual core processors. This
doubling of throughput means that a marginally slower clock rate is much less important for
computationally intensive HPC applications.
There is no significant change of instruction set between the two processors, but the
quad core processor has new floating point add and multiply units which can take full advantage
of SSE (Streaming SIMD
Extensions) instructions. There are 16 128-bit SSE registers in each core (for both processors)
for holding floating point operands. Thus either 4 single precision
numbers (32-bit) or 2 double precision numbers (64-bit) may be stored in the SSE registers.
SSE instructions are called either 'scalar' or 'packed'. Scalar instructions apply to
only one pair of numbers stored in two SSE registers, as illustrated in Figure 2.
Scalar instructions offer no performance boost over traditional x87 instructions.
However, packed SSE instructions apply to each pair of numbers stored in two SSE registers,
as shown in Figure 3. This is effectively a very short vector instruction, and compilers
often report the generation of packed instructions as code being vectorized.
In the dual core processors the floating point add and multiply functional units are 64-bits wide, and
thus able to process only half the data in SSE registers in one clock cycle.
The quad core processors have 128-bit wide floating point add and multiply functional units and
therefore have the ability to process the whole contents of a pair of SSE registers in one clock cycle.
This means that it is imperative to use packed SSE instructions in order to realise the performance
improvement available in the quad core processors.
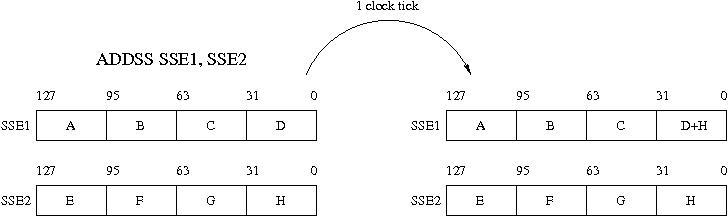
Figure 2: The operation of a single precision scalar add SSE instruction: two registers SSE1
and SSE2 hold four single precision (32-bit) numbers. The addition applies only to the low
end pair; the three high end numbers remain unchanged. The double precision
scalar instruction ADDSD would add the pair of numbers in bits 0-63.
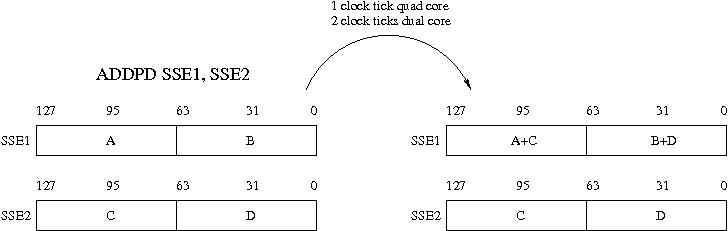
Figure 3: The operation of a double precision packed add SSE instruction: two registers SSE1
and SSE2 hold two double precision (64-bit) numbers. The addition applies to both pairs of numbers
in the registers. The single precision packed instruction ADDPS would add four pairs of numbers.
In order to feed this increased throughput, the quad core processor can perform two 128-bit loads
into SSE registers per cycle from the L1-D cache (rather than two 64-bit loads in the dual core
processor).
2. New Cache Hierarchy
The L2 cache acts as a victim cache for L1. This means that new data lines (i.e. those not already in
the cache hierarchy and coming from main memory) are loaded directly into the L1 cache.
Since L1 cache space is limited (only 64KB) other lines (least recently used) get evicted
into L2 cache as part of this load,
which is 1MB for the dual core processor, but only 512KB for the quad core processor.
The cache hierarchy ends here for the dual core processor, but the quad core processor has
a new 2MB third level of cache which is shared among all four cores and acts as a victim cache for
L2.
Loads of lines from L3 bypass L2 cache and go directly to L1. L3 is sharing-aware: if the line is
being accessed by only one core it is deleted from L3 to free up space; otherwise it remains.
Sharing L3 means that each core has more of the total cache hierarchy visible to it, with
the advantage that if a core needs more space it can generally have it, rather than depend on eviction.
The ability for cores to share cache lines provides more flexibility and scope for optimization.
3. New memory setup
Figure 1 indicates two changes to the memory setup:
an increase from 6GB (2x2GB DIMMs + 2x1GB DIMMs) to 8GB (4x2GB DIMMs) of memory per processor and
a faster transaction frequency, from 667MHz to 800MHz.
The change in configuration of DIMMs should provide a minor performance improvement due to traffic
being spread among DIMMs of the same size.
However, when considered on a per-core basis the new memory setup means 1GB less space and a 40%
decrease in bandwidth.
As discussed above, these statistics need to be considered in the
context of the whole upgrade: codes that scale well, use packed SSE instructions and the use cache
effectively should benefit from the new hardware.
Compiling for Quad Core
We recommend you recompile all your code for quad core. You should
load the module xtpe-barcelona. This will add the appropriate compiler
flags for targeting quad core to the ftn and cc wrappers. It will also link in
the quad core enabled version of libsci.
If you are compiling a hybrid OpenMP/MPI code then should explicitly link
to the multi-threaded quad core enabled version of libsci with
-lsci_quadcore_mp.
There is a PGI compiler flag that you may want to experiment with, which may or may not be beneficial. -Mfpmisalign allows vector arithmetic instructions with memory operands that are not aligned on 16-byte boundaries.
Batch Submission
If you wish to run on all cores of a node you must set the PBS option mppnppn
to 4. This is very important. If you leave the value as 2, then you will only
run on two cores per node, but be charged for 4.
A submission script for an MPI job running on Quad Core could look like this:
#!/bin/bash --login
#PBS -N My_job
#PBS -l mppwidth=32
#PBS -l mppnppn=4
#PBS -l walltime=00:03:00
#PBS -j oe
#PBS -A budget
cd $PBS_O_WORKDIR
export NPROC=`qstat -f $PBS_JOBID | awk '/mppwidth/ {print $3}'`
export NTASK=`qstat -f $PBS_JOBID | awk '/mppnppn/ {print $3}'`
aprun -n $NPROC -N $NTASK ./my_mpi_executable.x arg1 arg2
Similarly, if you are running a hybrid MPI/OpenMP job, using 4 OpenMP threads,
you would need:
#PBS -l mppnppn=1
#PBS -l mppdepth=4
For more information about submitting jobs please see the User Guide.
CSE Assistance
If you would like to explore how to take advantage of the potential performance increase
available in phase 2, or would like help benchmarking, profiling or improving your code, please get in touch
with the NAG CSE team:
hector-cse@nag.co.uk.
The CSE team run regular training courses on the topics discussed above, and more.
Check the schedule for current courses. If you would
like to attend a course not currently scheduled, please contact us.
Mon Jun 15 16:46:19 BST 2009