


Next: Scaling for equal grid
Up: NEMO on HECToR A
Previous: Visualising the NEMO output
Contents
NEMO performance
To investigate the performance of the NEMO code we run the code using
different numbers of processors and different grid configurations. We also
investigate whether the particular compiler used makes any difference. The
performance of NEMO is measured by examining the time.step file
output by the code. This reports the model step number and time taken in
seconds. The benchmark dataset runs for a total 60 model time steps and
so our benchmark data reports the time taken for 60 time steps.
All the the results presented in this section correspond to version 2.3
of NEMO. Results from version 3.0 of NEMO are presented separately.
The number of processors on which NEMO will be run is set in the source
file named, par_oce.F90. This file also sets up the grid
dimensions over which the model will be decomposed. The variables
jpni, jpnj, and jpnij specify respectively
the number of processors in the 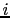 direction, the number of processors
in the
direction, the number of processors
in the 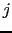 direction and the total number of processors. E.g. a 16x16
processor grid which runs on 256 processors would have jpni = 16,
jpnj = 16 and jpnij = 256.
direction and the total number of processors. E.g. a 16x16
processor grid which runs on 256 processors would have jpni = 16,
jpnj = 16 and jpnij = 256.
Subsections
Next: Scaling for equal grid
Up: NEMO on HECToR A
Previous: Visualising the NEMO output
Contents