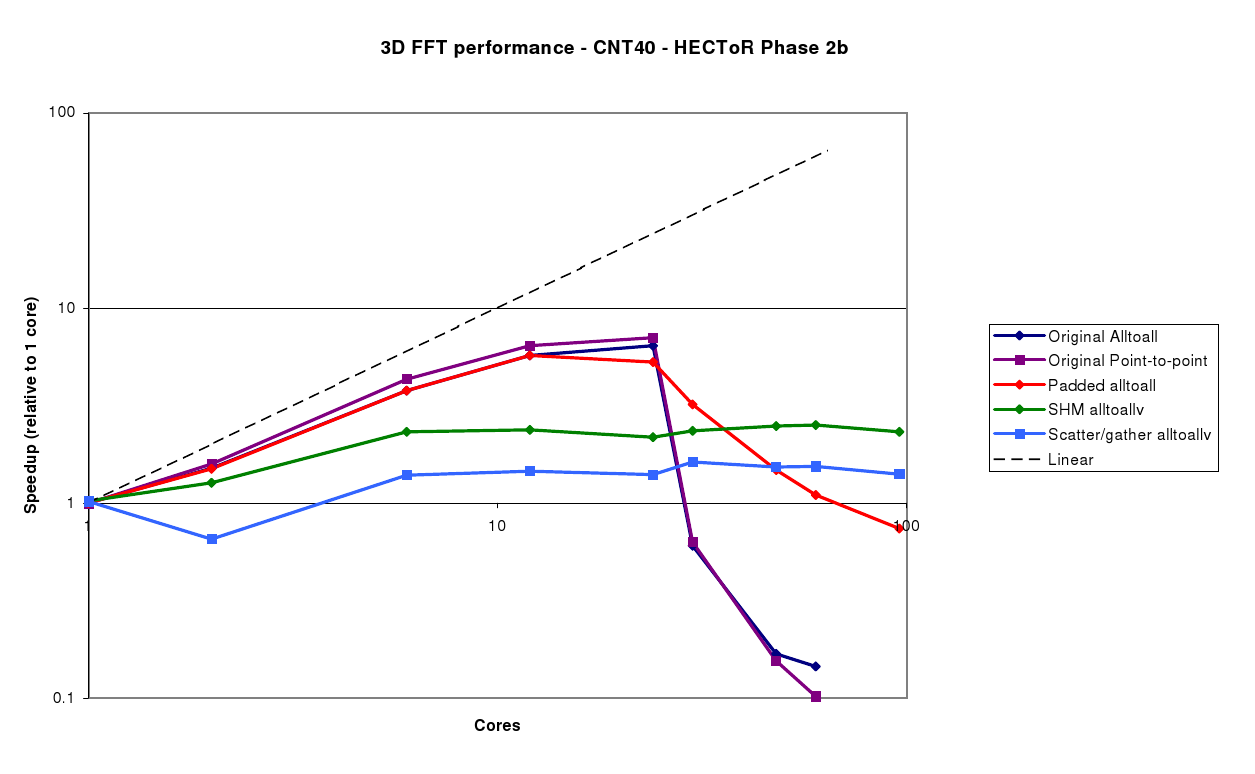
The same benchmarks were run on the HECToR Phase 2b system, with some significant differences in results. Starting with the CNT40 case (figure 6), whereas the original code only scaled up to 8 cores on the XT4, there is good scalability up to 24 cores on the XT6. This is due to the fact that there are now 24 cores on a single node, so all communication can go through the shared memory device rather than onto the network. However, beyond 24 cores, there is a very sharp drop-off in performance, as all 24 cores on the node attempt to send messages to another node. Cray's next generation `Gemini' interconnect, which will be added to HECToR Phase 2b in late 2010, promises to provide higher message throughput, so should go some way towards addressing this particular issue.
The Padded alltoall method does somewhat better beyond 24 cores, due to the reduced latency costs compared to the alltoallv, performance is still poor as the number of messages to be exachanged remains the same.
The SHM and Scatter/gather methods have even poorer performance when the number of cores is less than 24, but this level of performance is maintained to higher processor counts. However, as this is a relatively small system, with a grid size of 30 in each dimension, these results show it is best to use just a single node of the XT6 and avoid the inter-node communication entirely.
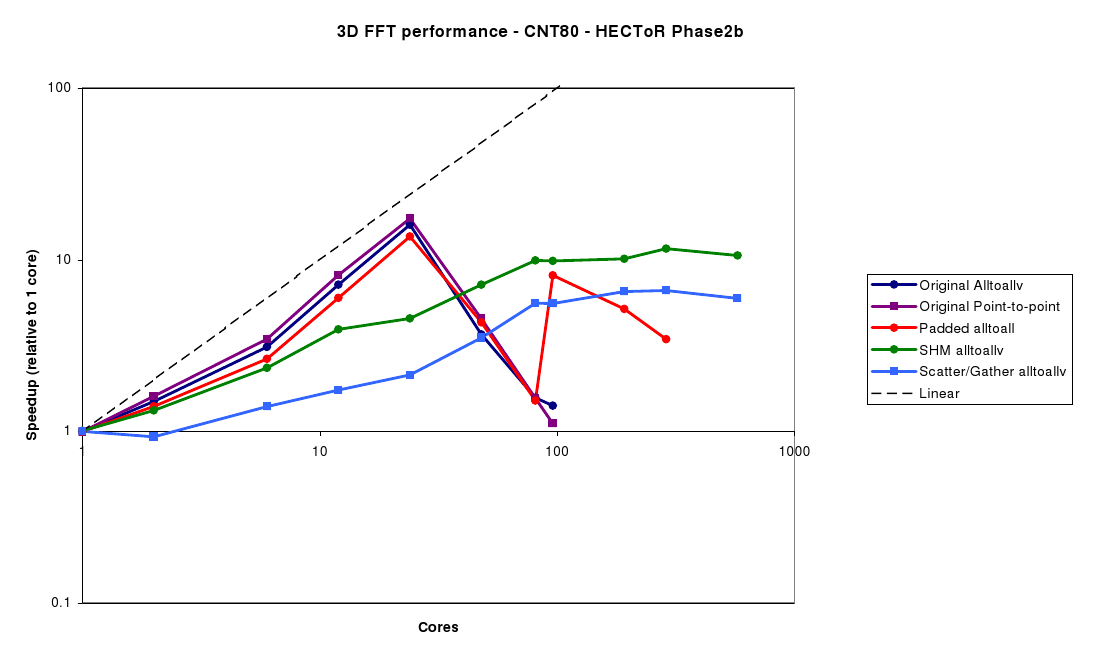
For CNT80 (figure 7), we see a similar drop-off beyond 24 cores for all the methods in which each core participates in the Alltoall communication. However, the padded alltoall does get some benefit at 96 cores and above from the switch to the store-and-forward algorithm.
The SHM and Scatter/gather code performs somewhat better for this larger example than CNT40, giving reasonable scalability all the way to 288 cores (12 nodes). It this case, there is a clear advantage in only using a single process per node for the communication, as the total number of messages drops from 82656 (of which 79488 would cross the network) to 132!
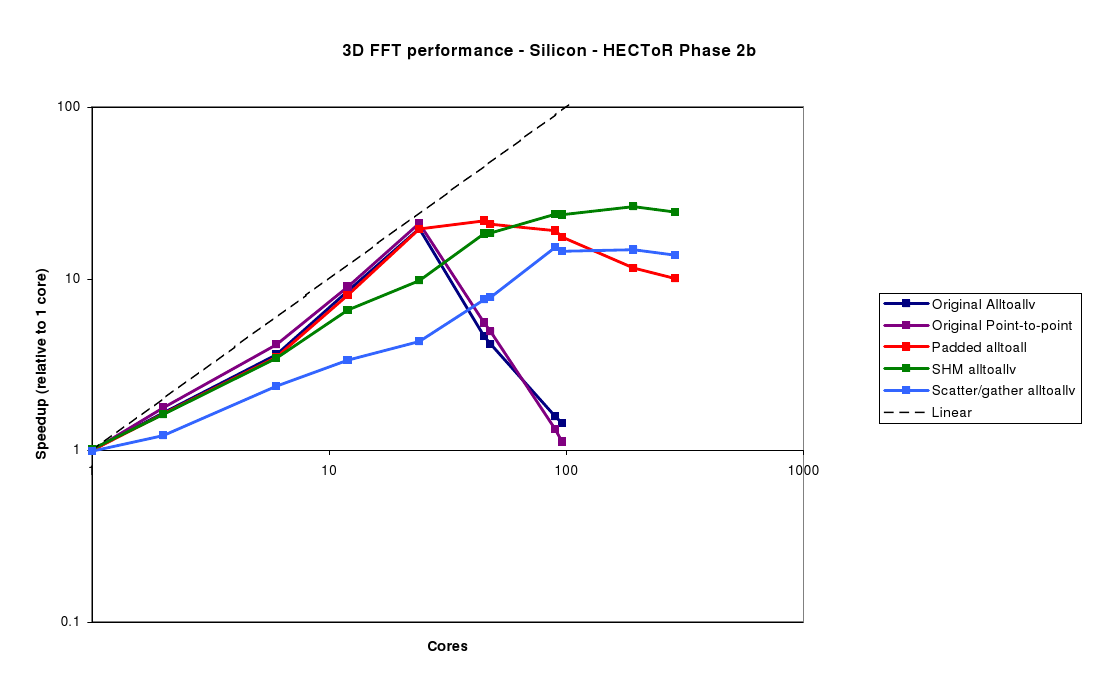
Finally, the Silicon benchmark (figure 8) again does not scale beyond 24 cores with the original code. Although the Padded alltoall does mitigate the drop-off in performance somewhat, to achieve better scalability (up to 288 cores), the SHM Alltoallv is required, similarly to the CNT80 case.