The scene graph contains general information (such as camera position, lighting, background colour) and also placeholders representing every renderable object that will eventually be created by the pstmpunode(p) parallel module processes. Renderable objects could be arrays of triangles for an isosurface or texture data for volume rendering, for example. The renderable objects are stored in a cache inside the rendering process and the placeholders in the scene graph reference objects in the cache. The scene graph is sent to every pstmpunode render process, as are messages that initiate update operations on the caches within those processes (for example, messages to delete out-of-date geometry objects). It is the communication of the scene graph and these messages that can be optimised.
When an image is to be rendered express determines whether it should generate
a scene graph containing new objects and geometry or whether it is simply
re-rendering an existing scene graph, perhaps with a change of camera
position. The former case occurs if, for example, the user changes an isosurface
level value or modifies a volume render transfer function. The renderer must
delete the existing cached objects and receive new ones from the module
processes. Messages must be sent to all render processes asking them to update
their caches so that all caches are consistent across the rendering
processes. In the latter case, where no new geometry is generated, a much
simpler scene graph can be distributed to the render nodes and no messages
requesting changes to the caches are required. In this case the scene graph will
reference existing geometry in the render nodes' caches but will include new
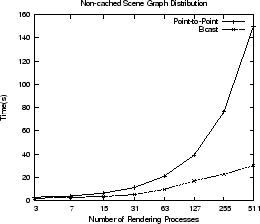
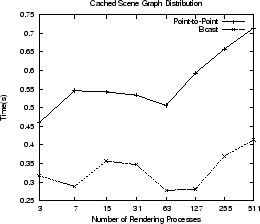
settings, such as the camera position. The graphs in figure ![]() show times for the communication of a non-cached new scene graph and a cached
scene graph, using the original point-to-point methods and the new broadcast
method. The non-cached scene graph times includes the time to generate and
communicate cache update messages to all rendering processes.
show times for the communication of a non-cached new scene graph and a cached
scene graph, using the original point-to-point methods and the new broadcast
method. The non-cached scene graph times includes the time to generate and
communicate cache update messages to all rendering processes.
The visualization for this test contains three isosurfaces of a standard AVS test dataset. The amount of geometry generated to represent the isosurface is not important because that geometry is communicated from the pstmpunode(p) processes to the render processes. We are interested in the messages from the express process to control render process caches and the distribution of the overall scene graph.
Replacement of point-to-point methods with MPI_Bcast is a simple but worthwhile optimisation. This change will benefit AVS/Express DDR on other platforms, not just HECToR, and has been submitted to AVS for inclusion in their source tree.
|