

Next: Parallel Renderer Communication
Up: Image Compositing
Previous: Image Compositing
Contents
Compositor Performance
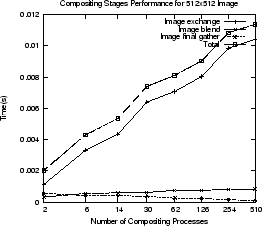
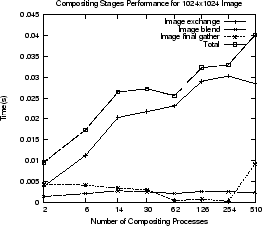
Figure ![[*]](icons/crossref.png) shows the performance of various compositing
operations. The top row shows timings for one particular rank for an image of
size
shows the performance of various compositing
operations. The top row shows timings for one particular rank for an image of
size 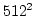 pixels and
pixels and 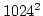 pixels. The rank chosen is the middle rank for
each number of render processes (any arbitrary rank could be used). This gives a
snapshot of what one particular render process is doing during image
compositing. All times are totals for the entire image compositing
operation. The Image exchange time is the total time the middle rank
process spends exchanging screen-space images with other processes during the
compositing operation. The Image blend time is the total time spent
blending image pixels (using depth testing). The Image final gather time
is time spent sending the blended sub-image to the single process (usually the
first pstmpunode render process) that gathers the sub-images from all other
render processes. Note that the gather operation writes the sub-images directly
in to the final image buffer. The Total time is the sum of the previous
three operations. Even the slowest compositing times correspond to a frame rate
of 90fps for a window and 30fps for a window.
pixels. The rank chosen is the middle rank for
each number of render processes (any arbitrary rank could be used). This gives a
snapshot of what one particular render process is doing during image
compositing. All times are totals for the entire image compositing
operation. The Image exchange time is the total time the middle rank
process spends exchanging screen-space images with other processes during the
compositing operation. The Image blend time is the total time spent
blending image pixels (using depth testing). The Image final gather time
is time spent sending the blended sub-image to the single process (usually the
first pstmpunode render process) that gathers the sub-images from all other
render processes. Note that the gather operation writes the sub-images directly
in to the final image buffer. The Total time is the sum of the previous
three operations. Even the slowest compositing times correspond to a frame rate
of 90fps for a window and 30fps for a window.
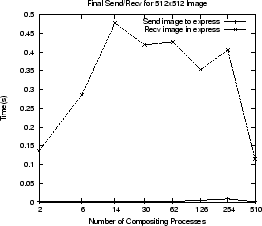
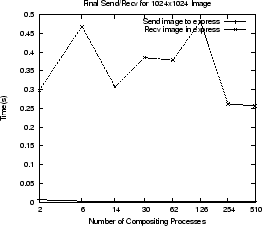
Figure:
Image compositing operations for two window sizes (top row). Final
composited image send / recv through the MPI proxy (bottom row).
|
|
The second row shows the time required for the express process to receive the
image through the MPI proxy, and the time for the single render process to send
the image to the proxy. The sending time is small because this is
occurring within the Cray MPI layer. The receiving time is significant and will
limit the overall frame rate of the renderer. This image transfer occurs over
the tcp/ip socket through which express and the MPI proxy process
communicate.
We have added an OpenMP wrapper around the Paracomp library's core image
compositing routine. This allows the blending time to be reduced in the
compositing operation for large images. A trade-off is needed between the number
of pstmpunode processes running on a node (usually two or four) against the
number of OpenMP threads dedicated to image blending. However, given that the
image transfer from the MPI proxy to express is the limiting factor, it is
recommended that only one OpenMP thread be used. This allows the number of
pstmpunode processes on a node (mppnppn) to be increased.
Next: Parallel Renderer Communication
Up: Image Compositing
Previous: Image Compositing
Contents
George Leaver
2010-07-29