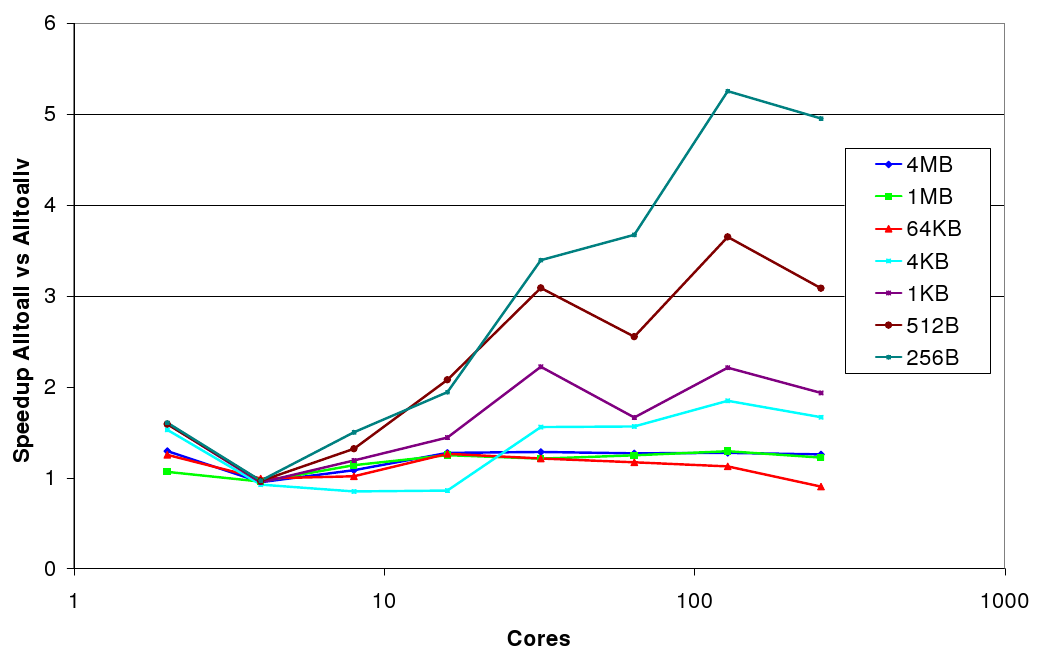
The second approach is motivated by the fact that although differing amounts of data are sent and recieved by each process, requiring the use of MPI_Alltoallv (see section 4), if the data was padded such that every process sent and recieved the same amount of data, MPI_Alltoall could be used instead. For `short' messages, MPI_Alltoall uses an optimised algorithm, known as `store and forward' which trades off increased bandwidth usage for a reduction in message latency. Specifically, whereas the default algorithm's cost scales as O(p+n), where p is the number of processes and n is the message size, the store and forward algorithm scales as O( log(p)+nlog(p)). When the number of processes is large, and the message size is small, the is expected to give a significant performance improvement, which should overcome the cost of sending the extra padding data. This can be seen clearly in figure 2, which shows that when the message size is sufficiently small, MPI_Alltoall is significantly faster than MPI_Alltoallv - in fact up to 5 times faster, for 256B messages on 256 cores.
In fact, using the same example as before (CNT40 on 16 cores), the total data size being sent by all processes is 1232 elements (20kB). If each process has additional padding added to equal the largest individual send size, the total data to be sent is now 1344 elements, only a 9% increase in the total volume of data. For messages of this size (1kB), the bandwidth component of an individual message is of order 10-7 compared with the latency of order 10-6, so the extra cost associated with the padding is negligable.
The Padded alltoall requires much less additional calculation that then SHM approach, as each process already has all the data needed to calculate the global maximum message size. Once the buffers are packed, data is sent using a call to MPI_Alltoall, then unpacked. By ensuring that the real data is always at the start of the block of data sent between processes (and the padding is at the end), it is easy to just read only the amount of data that would be expected if the communication had been done using MPI_Alltoallv, and ignore the padding.
Compiling the code using Padded Alltoall requires the __FFT_ALLTOALL macro to be defined at compile time.