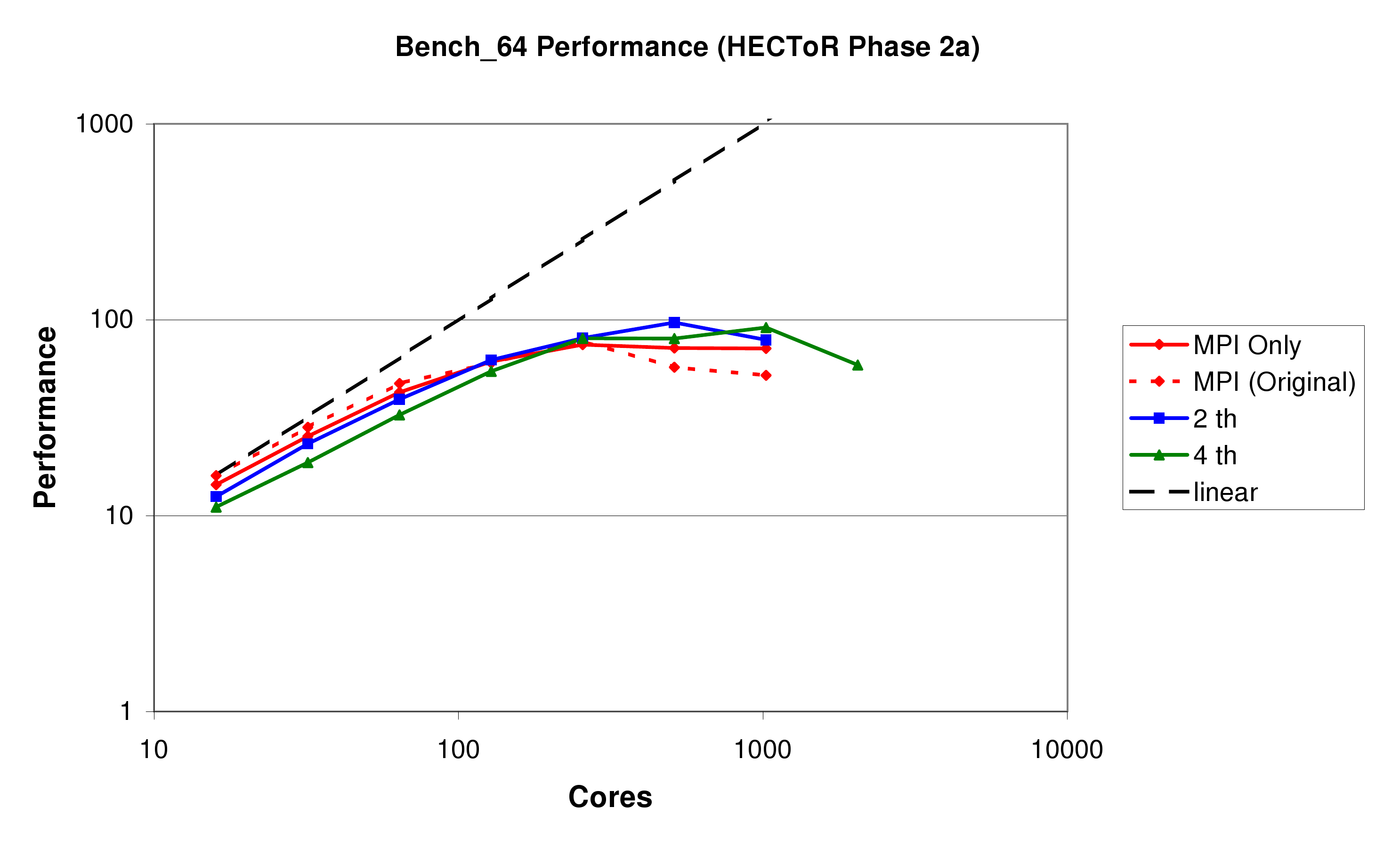
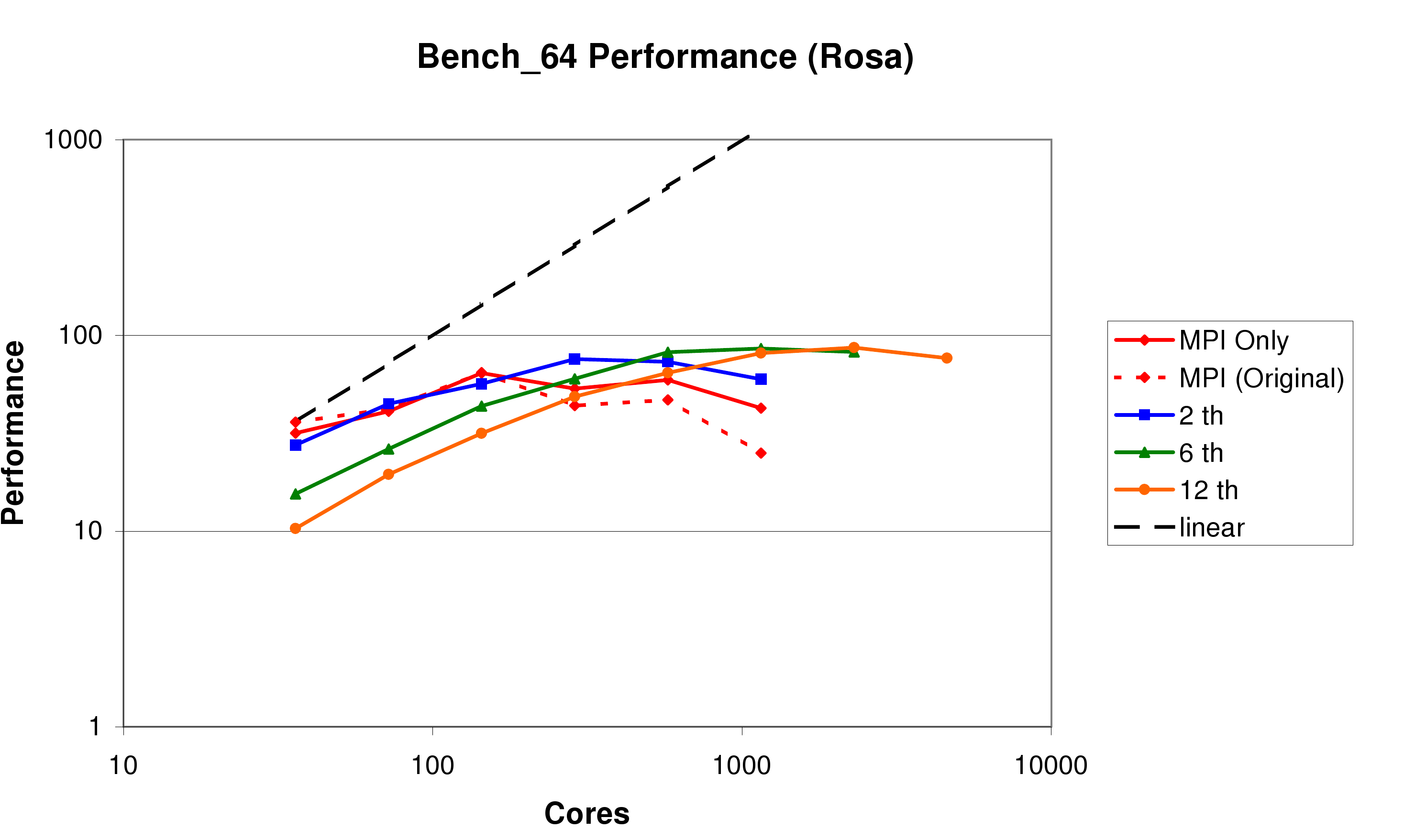
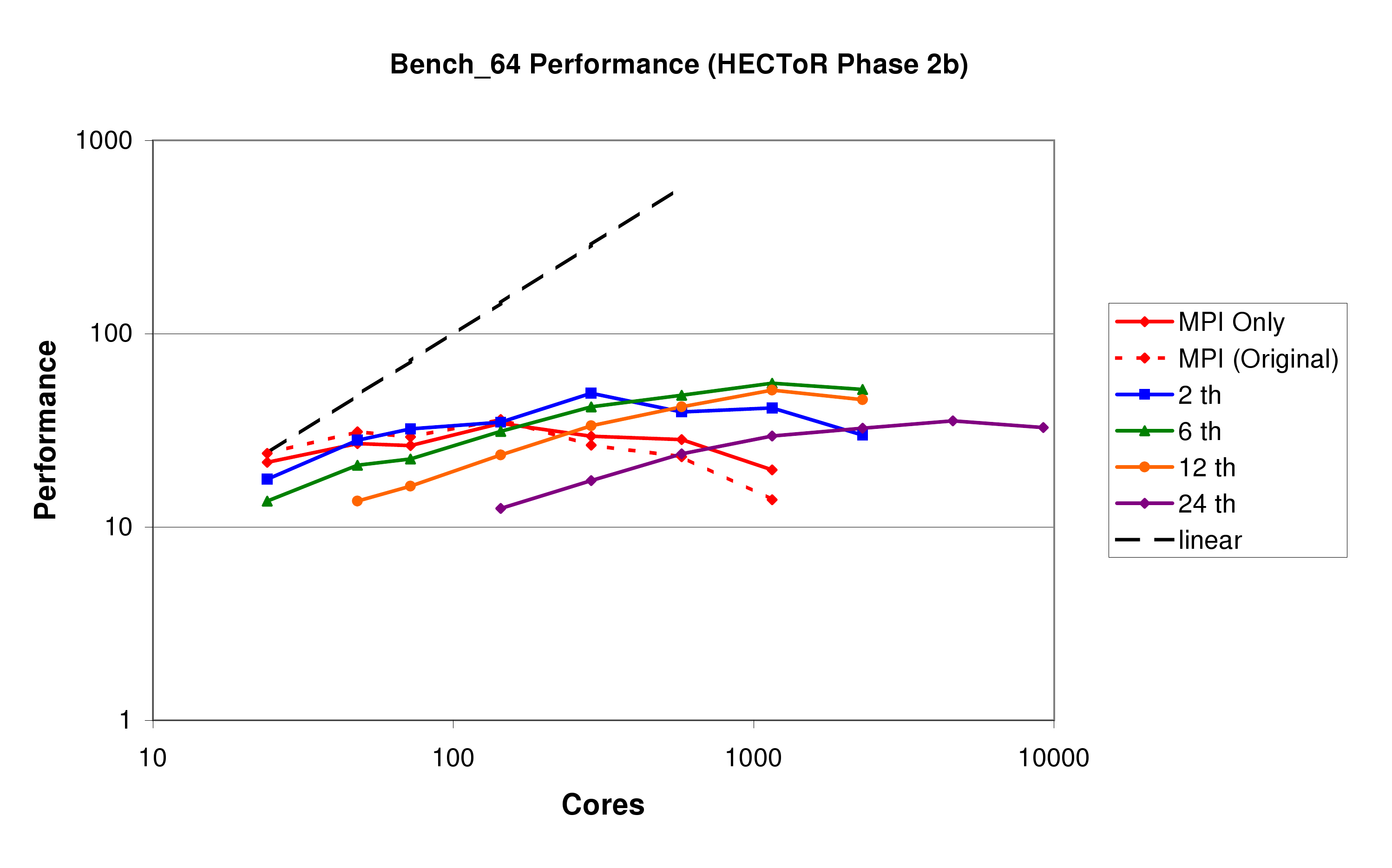
In this section we present some benchmark results on all three Cray systems, HECToR Phase 2a (figure 8), Rosa (figure 9), and HECToR Phase 2b (figure 10). Again, it should be stated that as well as the work reported here, these benchmarks also include the results of other development on CP2K, in particular the DBCSR library.
Firstly it is clear from comparing the three systems that as the number of cores in a node increases (4 in HECToR 2a, 12 in Rosa, 24 in HECToR 2b), the scalability of the code decreases, with the maximum performance of the pure MPI code being achieved on 256, 144, and 144 cores respectively. We note, however, that the Seastar 2+ network interface (used by all three systems), is soon to be replaced by the new Gemini interconnect on HECToR Phase 2b. This will bring higher message throughput, and also especially improved performnace for small messages. We expect this to give scalability similar to or better than the XT4.
Secondly, we see that the performance of the MPI-only code has improved by 40-70% at around 1000 cores. While this has not had the effect of allowing the MPI code to scale any further, it will help improve performance at higher core counts for larger problems.
Thirdly, we see that using threads does indeed help to improve the scalability of the code. Suitable numbers of threads to use are between 2 and 6 (the number of cores in a single processor), depending on the balance between performance for low core counts, and the desired scalability. The overall peak performance of the code has been increased by about 30% on HECToR Phase 2a and Rosa when using mixed-mode OpenMP, and by 60% on HECToR Phase 2b, due to the fact that it reduces the number of messages being required to pass through each SeaStar dramatically.
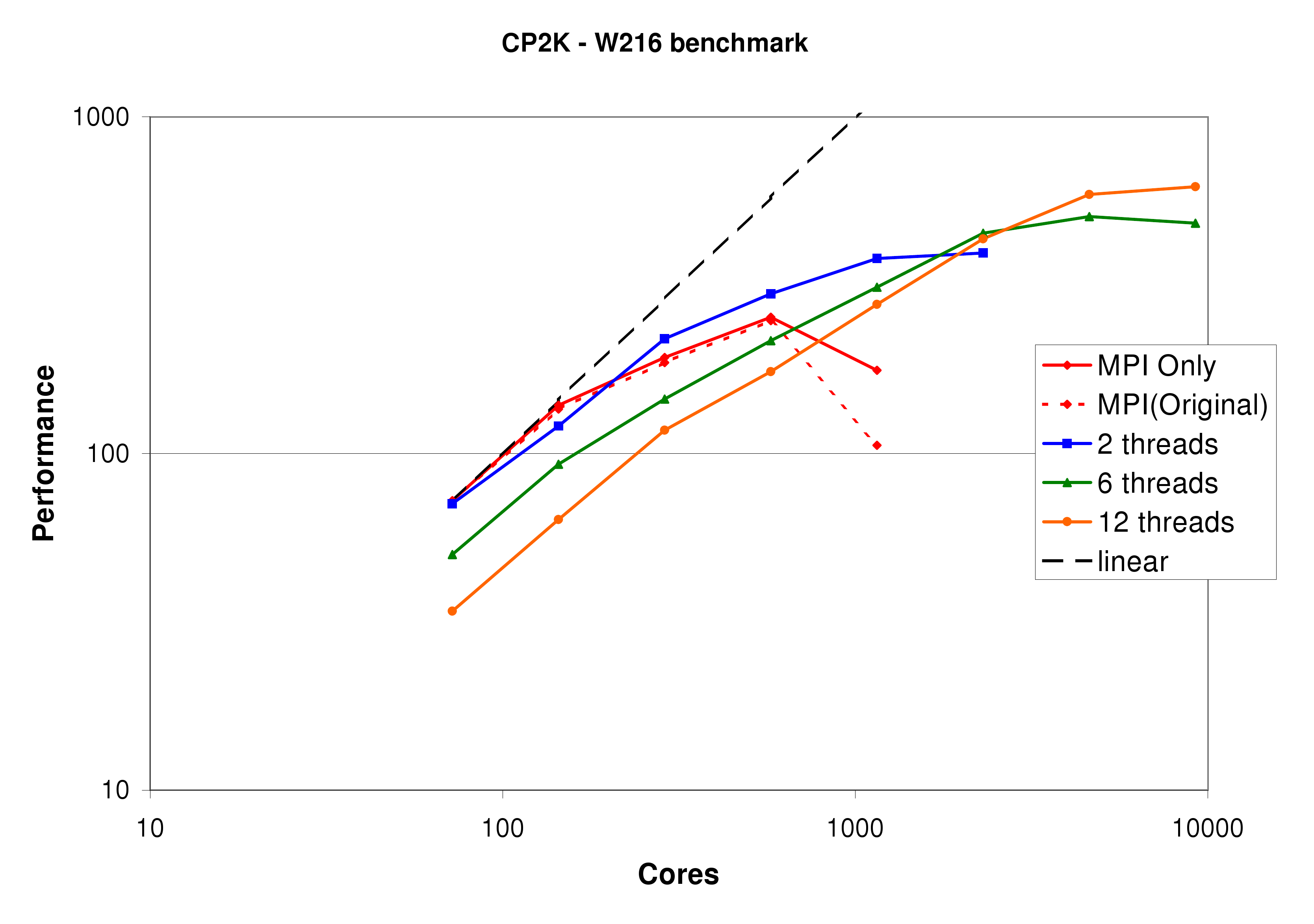
Figure 11 shows the performance of the W216 benchmark on Rosa. W216 is a larger system than bench_64, having 3 times as many atoms, and a unit cell of 20 times the volume. Here the benefits of using a mixed-mode approach are shown very clearly. Using only a single MPI task per node, with 12 OpenMP threads, the maximum performance achieved is 2.5 times that of the pure MPI code. This does come at a premium in terms of efficiency however, as to achieve the speedup 16 times as many cores are used. However, using 2 threads per task it is possible to achieve a genuine speedup of 20% on 576 cores.