Next: Improving the I-O in Up: Optimising the Potential vorticity Previous: Implementation Contents
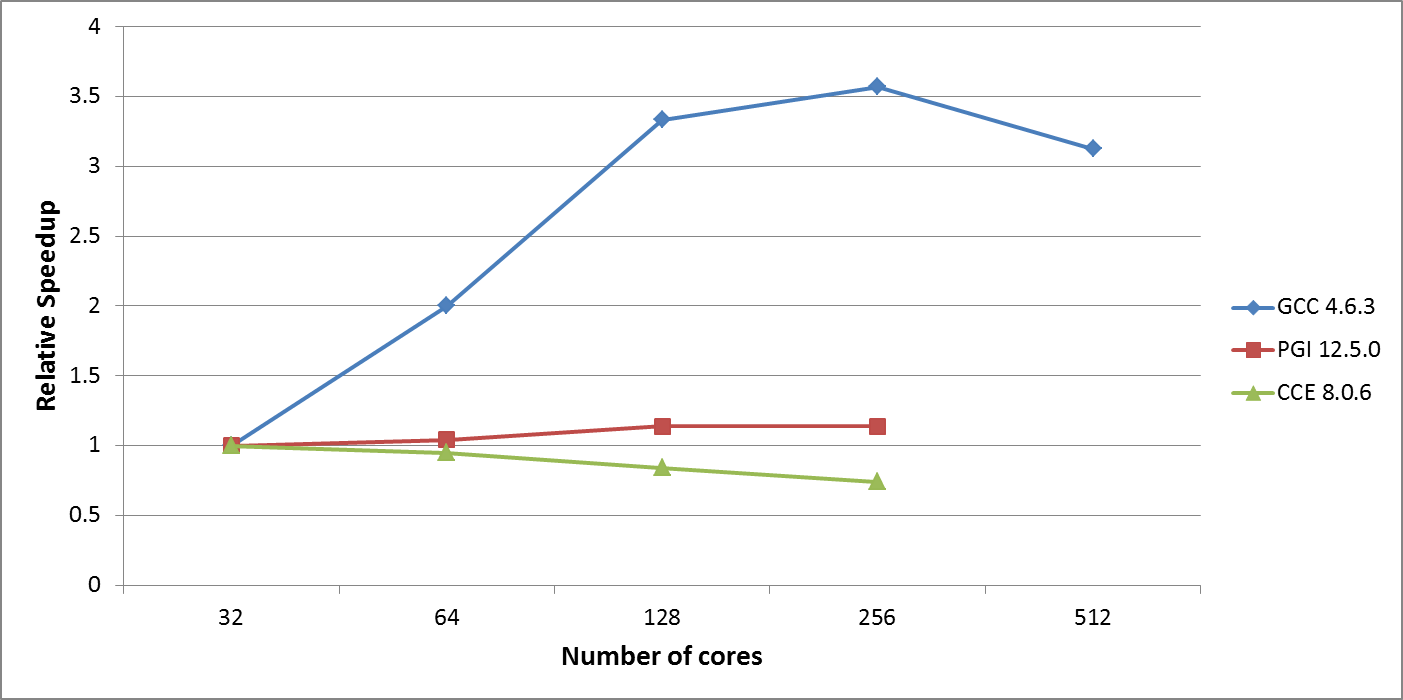
Scalability of the new MPI_ALLTOALL implementation is shown in Figure 2, here it shown that the strong scalability for the benchmark test case in WP2 is now good up to 256 cores on HECToR Phase 3, whereas it was initially limited to use on only 64 cores. It is also worthwhile noting that although performance with PGI is not as good, there is improved scalability. Although CCE does not show any increase in scalability and the results are similar to those shown in Figure 1 with MPI_ALLTOALLW.
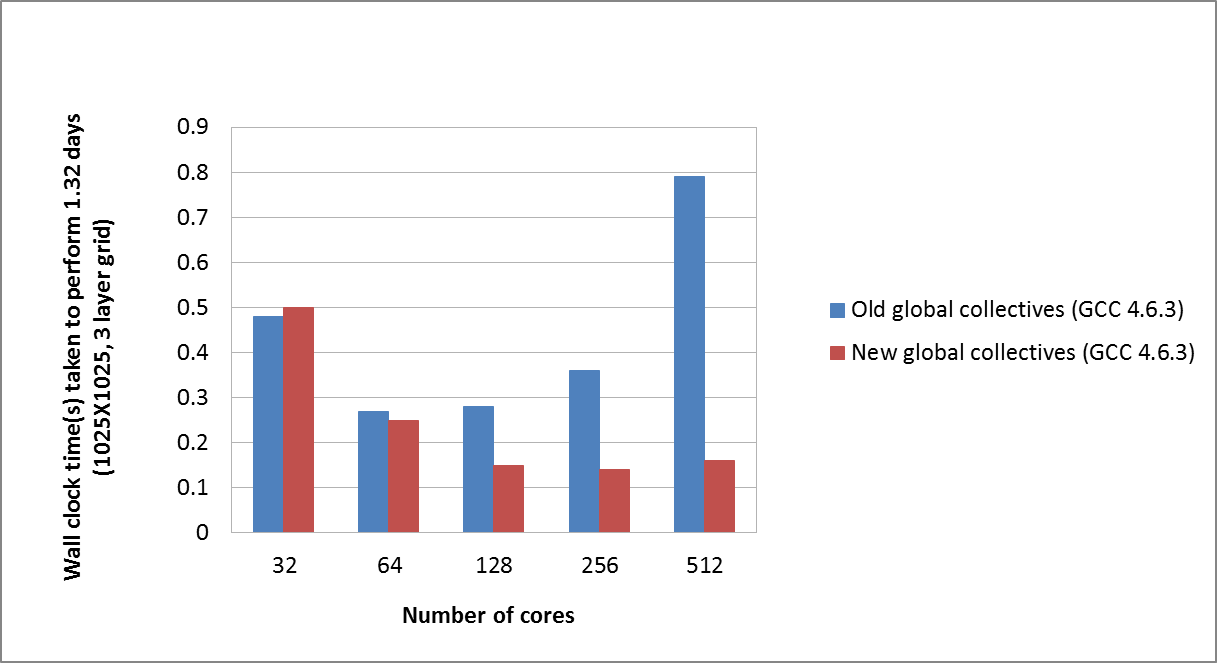
An exact comparison of the old and new implementations is shown in Figure 3, here it is easy to see that although the underlying trend is the same for both implementations, the cost of communication has been dramatically reduced with the new global collectives.
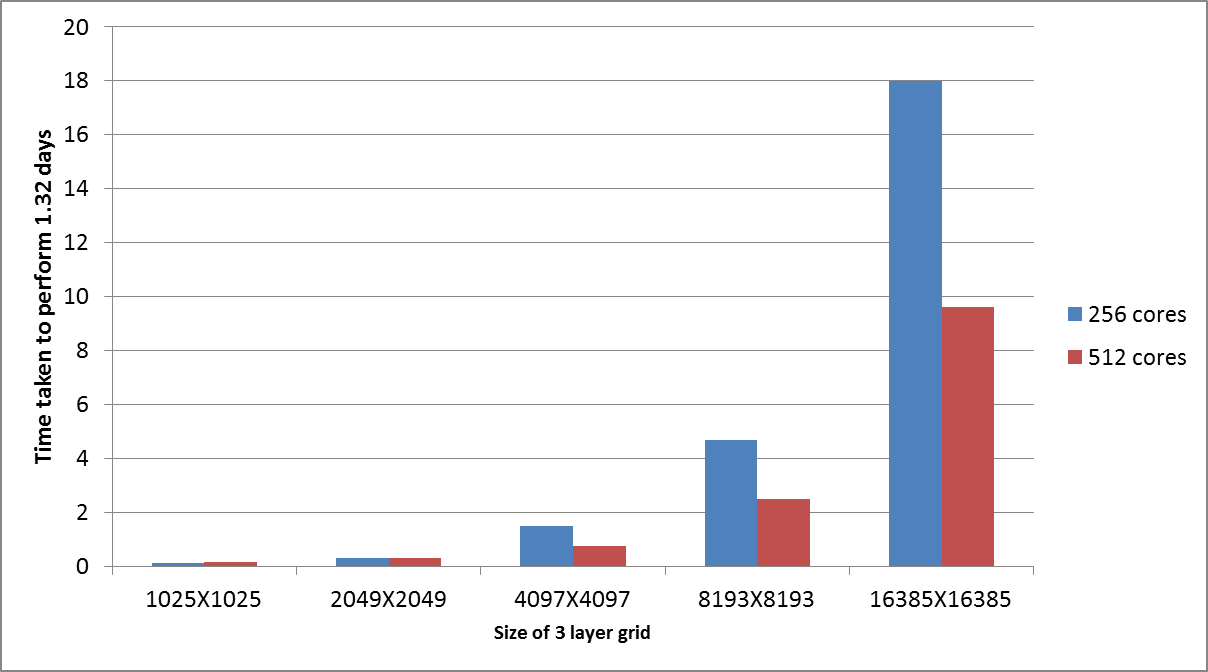
For strong scalability the performance of the new implementation has been demonstrated to be consistent up to problem sizes of 16385 (this is the maximum tested). These results are shown in Figure 4, with all runs being performed with code compiled using GCC 4.6.3.
Phil Ridley 2012-10-01