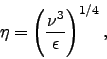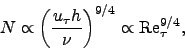Prior to the completion of this project, the SWT and SSF3D programs both used a 1-D domain decomposition. The domain is divided into 2-D slices; this permits FFTs in two dimensions but not the third, so a parallel transpose is required to transform the decomposition to another one, also of 2-D slices, but differing in one dimension.
3-D Fourier transforms are implemented here as 3 successive 1-D transforms. There is therefore no need for an individual processor to have access to more than one dimension at a time. Decomposing the domain into `pencils' - a 2-D domain decomposition, into elements with two incomplete dimensions - would obviously increase the maximum number of processors that could be used.
However, this approach comes at a cost; an additional parallel transpose is required for every transform. The 1-D decomposition therefore remains attractive at low processor counts, though it restricts the number of processors that can be used, to, at most, the number of collocation points in one of the three spatial dimensions. As the grid is refined, however, the memory required, as well as the computational expense per time step, increases with the cube of this number. The processor count, meanwhile, can only scale linearly.
In practice the situation is even less favourable, as, in general, two different 1-D domain decompositions are required; if (as is usually the case) the numbers of collocation points in each direction are not the same, the greatest useful processor count is set by the lower of the two numbers chosen. Also, further load balancing issues arise if either one of these numbers is not exactly divisible by the processor count, and the latter is high (so that the imbalance is significant relative to the total workload).
These considerations limit simulations using SWT and SS3F to a few hundred processor cores at present, which results in relatively low performance in terms of wall clock time required to perform a physically realistic simulation. The most serious consequence, however, is that the scaling of memory requirements - doubling the resolution in all three directions permits at most a doubling of the core count, but guarantees the octupling of the total memory required. The expected reduction in the ratio of memory to core count arising from the increasing prevalence of multicore architectures only exacerbates the problem.
The applicability of turbulence simulations to the real world depends critically on good grid resolution (see [14] for a counterexample). In its absence, fidelity must be compromised, or the problem to be studied modified in some way - for instance, by a reduction in Reynolds number, which could adversely affect the generality of the result.
The Reynolds number is the parameter governing the range of scales present in a direct simulation of turbulence. The grid resolution required for a particular problem is expected to scale with this number. The required number of collocation points
where ![]() is the integral length scale of the largest eddies, roughly
proportional to the channel height
is the integral length scale of the largest eddies, roughly
proportional to the channel height ![]() , and
, and ![]() , the
Kolmogorov scale, is that of the smallest, equal to
, the
Kolmogorov scale, is that of the smallest, equal to
where ![]() is the viscosity, and
is the viscosity, and ![]() the dissipation rate.
In the case of the channel flows the SWT code is designed to simulate,
the following is approximately true:
the dissipation rate.
In the case of the channel flows the SWT code is designed to simulate,
the following is approximately true:
where ![]() is the friction velocity at the wall, equal to the square
root of the ratio of wall shear stress and fluid density,
is the friction velocity at the wall, equal to the square
root of the ratio of wall shear stress and fluid density,
![]() .
Substituting 5 into 4 and 3,
we obtain
.
Substituting 5 into 4 and 3,
we obtain
where Re is the Reynolds number. The memory requirements of a simulation therefore
scale as
![]() , however, because the time step must also be reduced
to resolve the smallest eddies.
, however, because the time step must also be reduced
to resolve the smallest eddies.
Using the same assumptions made above to obtain the
lengthscale ratio, we may derive a ratio of large to small time scales ![]() ,
where
,
where ![]() is the ratio of
is the ratio of ![]() to the mean flow velocity
to the mean flow velocity ![]() (assumed above roughly
(assumed above roughly
![]() ) and the Kolmogorov time scale
) and the Kolmogorov time scale
![]() . This
turns out to vary as
. This
turns out to vary as
a finding confirmed by the computational results of Kim et al [10].
This has implications for the scaling of computational workload with Reynolds number - i.e. that it is nearly cubic - but also for the scaling of total computational workload with grid points, namely that it is superlinear. If domain decomposition alone is relied upon for parallelisation, then - absent improvements to parallel scaling - we can probably only hope to scale the processor count with the size of the grid. A complete DNS is not, therefore, expected to scale in accordance with Gustafson's law [7], which requires a constant workload per processor - performance over a fixed number of time steps, however, may do so, if the solution algorithm scales linearly in the number of grid points.
For a DNS as a whole, Snyder's [13] Corollary of Modest Potential applies; the problem takes
time steps ![]() , and the work per grid point varies at least in the same proportion (assuming,
optimistically, an
, and the work per grid point varies at least in the same proportion (assuming,
optimistically, an ![]() algorithm).
The total work, or wall clock time, would be
algorithm).
The total work, or wall clock time, would be
This is a limitation essentially imposed by the physics of turbulence;
algorithms with scaling in ![]() inferior to
inferior to ![]() would raise the exponent further,
and time integration schemes with stability constraints might do the same.
would raise the exponent further,
and time integration schemes with stability constraints might do the same.
If the application of ![]() processors permits an increase in the problem
size by a factor
processors permits an increase in the problem
size by a factor ![]() , then
, then
and, if we require the wall clock time ![]() to remain fixed,
to remain fixed,
Doubling ![]() , therefore, allows at best an increase of 76% in
, therefore, allows at best an increase of 76% in ![]() , which permits, as long
as 6 holds, about a 29 % increase in Re. Large increases in
, which permits, as long
as 6 holds, about a 29 % increase in Re. Large increases in ![]() are
therefore needed to allow significant increases in Re, and so good parallel scaling is
mandatory.
are
therefore needed to allow significant increases in Re, and so good parallel scaling is
mandatory.
Note further that for DNS of wall bounded turbulence, the ratio ![]() that needs to be simulated
may increase faster with Re than is indicated by the relationship 6 given
above. The reason for this is that the very largest scale motions in such flows do not
measurably affect flow statistics at low Re [8], so that a low Re DNS
may employ a domain too small to capture them; but this ceases to be true at higher Re.
The Reynolds numbers that have so far been considered using DNS are believed to fall, on the whole, into
the former category.
that needs to be simulated
may increase faster with Re than is indicated by the relationship 6 given
above. The reason for this is that the very largest scale motions in such flows do not
measurably affect flow statistics at low Re [8], so that a low Re DNS
may employ a domain too small to capture them; but this ceases to be true at higher Re.
The Reynolds numbers that have so far been considered using DNS are believed to fall, on the whole, into
the former category.
This implies that such simulations as have already been performed are not fully independent of Re, and the results therefore lack a degree of universality that might be (and, on the basis of experimental work, is) expected at higher Re. Experimental data do not contain the same information as DNS, and so cannot always be used to address the same questions. It is therefore desirable to carry out such simulations. However, the difficulty of scaling Re implied by 6 and 11 above, added to the need to resolve still greater turbulent lengthscales, does call into question the feasibility of doing so.