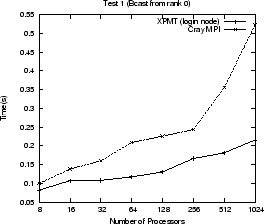
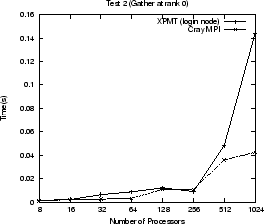
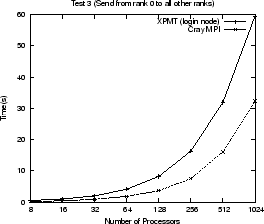
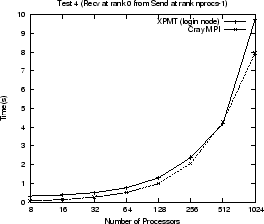
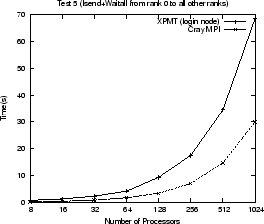
Use of the MPI proxy imposes a performance penalty on any MPI communication to
and from the express process. Figure ![]() shows execution times
for various tests using the proxy and the standard Cray MPI layer. A Cray MPI
executable was used entirely on backend nodes. The same tests were compiled
against the XPMT replacement library so that what was rank 0 now runs on the
login node and communicates via the xpnode proxy processes (which becomes rank
0 in the MPI job). The remaining ranks are standard Cray MPI executables. This
matches exactly the changes made to AVS/Express. The tests perform common
communication calls (MPI_Bcast, MPI_Gather, MPI_Send, MPI_Recv, MPI_Isend,
MPI_Irecv, MPI_Waitall) that are all found in AVS/Express. They each send or
receive using an array of MPI_INTs where the size of the array increases
as: 64, 128, 256, 512, 1024, 1024
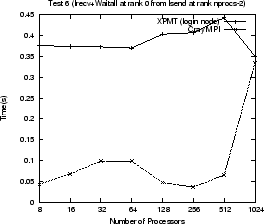
shows execution times
for various tests using the proxy and the standard Cray MPI layer. A Cray MPI
executable was used entirely on backend nodes. The same tests were compiled
against the XPMT replacement library so that what was rank 0 now runs on the
login node and communicates via the xpnode proxy processes (which becomes rank
0 in the MPI job). The remaining ranks are standard Cray MPI executables. This
matches exactly the changes made to AVS/Express. The tests perform common
communication calls (MPI_Bcast, MPI_Gather, MPI_Send, MPI_Recv, MPI_Isend,
MPI_Irecv, MPI_Waitall) that are all found in AVS/Express. They each send or
receive using an array of MPI_INTs where the size of the array increases
as: 64, 128, 256, 512, 1024, 1024![]() , 2
, 2![]() 1024
1024![]() and 8
and 8![]() 1024
1024![]() (the Gather test uses array sizes up to 512). The graphs show the total time for
all array sizes used for each test. The use of the MPI proxy can slow
communication by a factor of three, approximately, in some cases. Within
AVS/Express most of the messages from the express process are less than 1K in
size. The largest message sent back to the express process from the compute or
render nodes is usually that containing the final composited rendered image,
which for a 512
(the Gather test uses array sizes up to 512). The graphs show the total time for
all array sizes used for each test. The use of the MPI proxy can slow
communication by a factor of three, approximately, in some cases. Within
AVS/Express most of the messages from the express process are less than 1K in
size. The largest message sent back to the express process from the compute or
render nodes is usually that containing the final composited rendered image,
which for a 512![]() 512 window is 1Mb (assuming 4 bytes per pixel). Given
that AVS/Express is an interactive application (rather than a numerical
simulation) we find this performance penalty acceptable.
512 window is 1Mb (assuming 4 bytes per pixel). Given
that AVS/Express is an interactive application (rather than a numerical
simulation) we find this performance penalty acceptable.
|