Next: Summary Up: Band Parallelism Previous: Triangular Matrix Optimisations Contents
In order to improve the communication time, two major changes were implemented. Firstly
the original, naive communication pattern was replaced with a systolic loop (a ring topology); secondly
the blocking, synchronous communications were replaced with non-blocking, asynchronous communications.
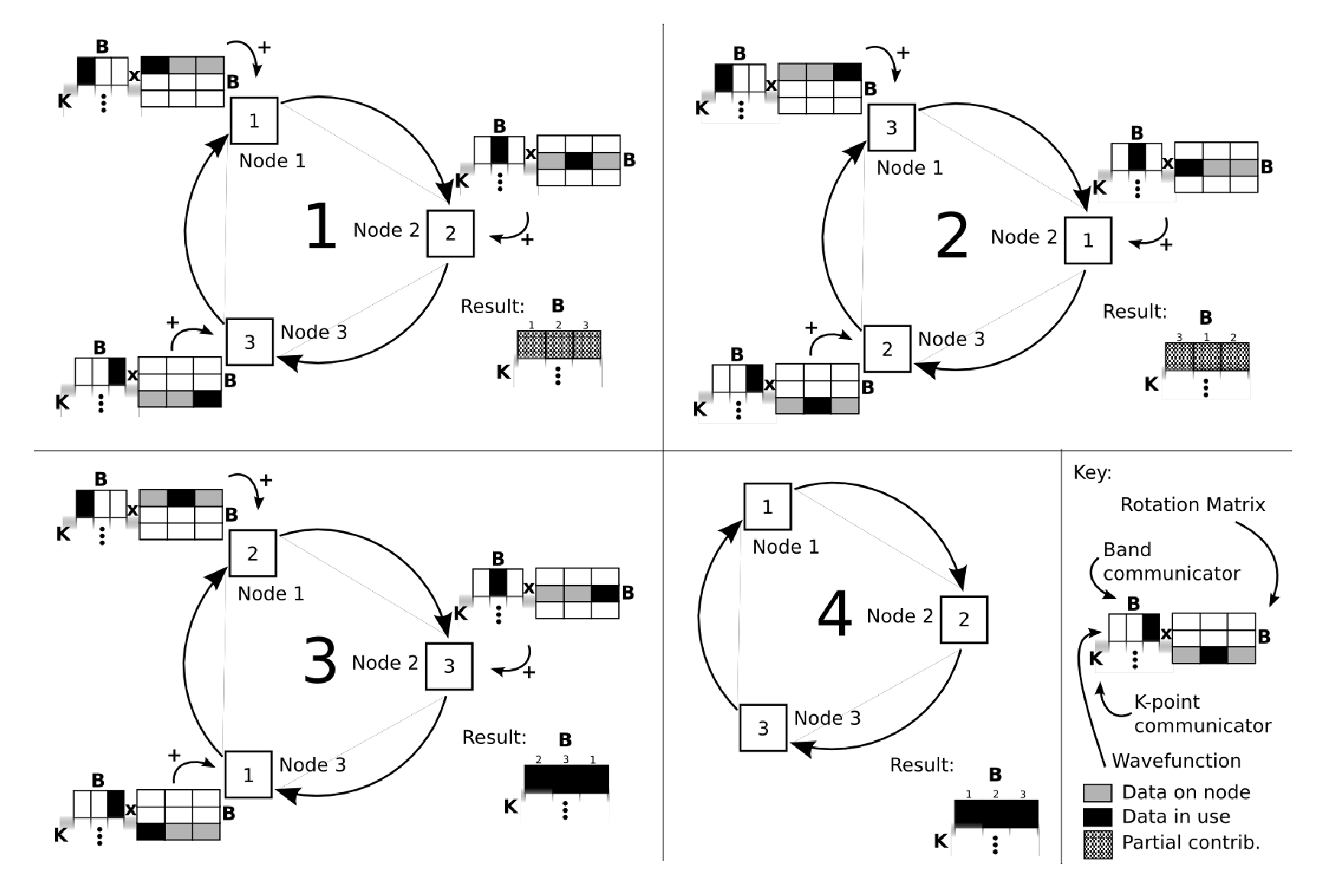
The systolic algorithm for a three-way band communicator is shown in Figure 1.The final
(or initial) stage is move the data one step around the systolic loop, to its corresponding node.
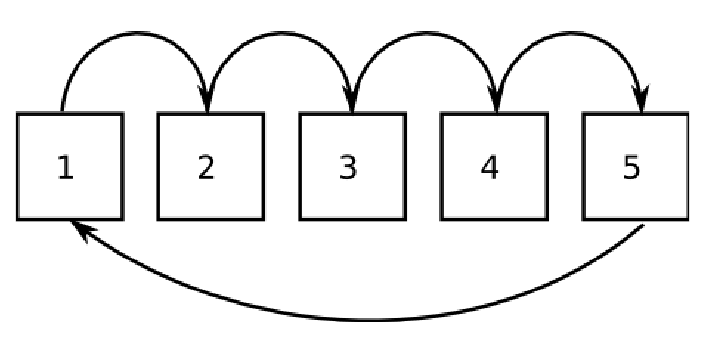
The performance of the initial implementation of the systolic loop was disappointing. In this initial
implementation core n in the band group has neighbours in the systolic loop that were cores n-1 and n+1, modulo the total
number of cores in the band group (as shown in Figure 2). Unfortunately this means for N total cores
in the band group, each loop communication phase involves communications between core N and core 1, which is likely to
be the longest route in the actual hardware topology; since the systolic algorithm is essentially synchronous, it is
limited in speed by the longest communication.
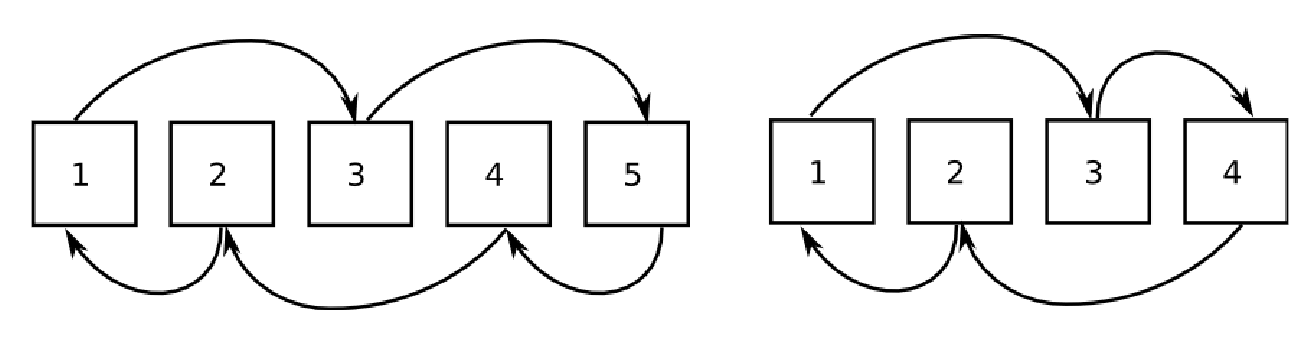
To improve the performance, the systolic loop was reordered so that all the odd-numbered cores have odd neighbours, and the even cores have even neighbours, with the exception of the lowest and highest numbered cores (as shown in Figure 3). This increases the average distance between neighbours, but decreases the longest distance; in fact almost all communications are between cores that are 2 apart in the band-numbering. By reducing the time of the worst-performing communication, each communication phase of the systolic loop was much quicker.
After testing, it was also found that reordering the gv- and bnd-groups was beneficial, so that
consecutive MPI threads were in the same bnd-group rather than the same gv-group.
This data was collected for a system with 768 bands as shown in Table 4, and serves to show that the scaling is better with the new algorithm. The scaling advantage will come into its own when much larger systems are simulated, as there will be far more work to do per core and far more data to pass around. Triangular matrix optimisations were turned off to show the effect of the systolic algorithm alone.