The scheme outlined above works well for calculations over 2 or 3 nodes, but as the number of nodes increases the time taken by the communication calls also increases. If we look at the profiles from Castep's internal trace for wave_rotate_slice on a 4-node calculation (table 4.1) we can see that the higher-numbered nodes are spending more time in the subroutine than the lower-numbered ones.
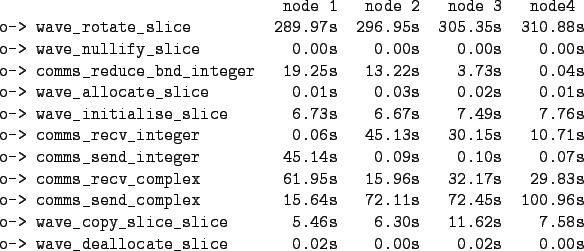 |
The reason for this disparity is that by constructing all of the data for a given node before moving onto the next node, we `serialise' the communication calls-each communication phase is one-to-many or many-to-one, and because Castep uses standard MPI_send and _recv calls every node has to wait for all of the preceding nodes to finish their communications before it can begin. This process proved to be a severe bottleneck for calculations over large numbers of nodes.
Removing this bottleneck is straightforward-we simply copy the
communication pattern from the dot-all subroutines. The communication
pattern is now a cyclic one, where every node constructs the data for
a node ![]() hops prior to it. For each
hops prior to it. For each ![]() there are two sets of
communications, each of two phases. The first communication set
consists of each node sending its rotation matrix
there are two sets of
communications, each of two phases. The first communication set
consists of each node sending its rotation matrix ![]() places to the
left, and receiving a rotation matrix from
places to the
left, and receiving a rotation matrix from ![]() places to the right
(there is also some exchange of meta-data). Each node then applies the
rotation matrix it received to its local data. In the second
communication phase each node passes the result of its rotation
places to the right
(there is also some exchange of meta-data). Each node then applies the
rotation matrix it received to its local data. In the second
communication phase each node passes the result of its rotation ![]() places to the right, and receives the contribution to its own
transformed data from
places to the right, and receives the contribution to its own
transformed data from ![]() places to the left.
places to the left.
All of the communication phases are now point-to-point, and many such communications can take place simultaneously.