Next: Conclusions Up: Improving the parallelisation and Previous: Second parallelism level with Contents
We describe briefly the improvements implemented in the input subroutines which read various data sets at the beginning of a computation. The algorithms used are straightforward though laborious to implement.
CASINO versions older than 2.4 uses ASCII input files to store BC
data. For system with more that 1000 electrons the reading of this
file could take more that 30 minutes which is rather a significant
fraction of the maximum allowed run time (12 hours). If the input data
file is converted to binary format the reading time drops below 30
seconds. Also an MPI-IO version of this file can be used. This is useful for
calculations using MPI-2S algorithm, described in Sec ![[*]](crossref.png) , for
only one file is needed to store the BC for any value of the number of
task per group.
, for
only one file is needed to store the BC for any value of the number of
task per group.
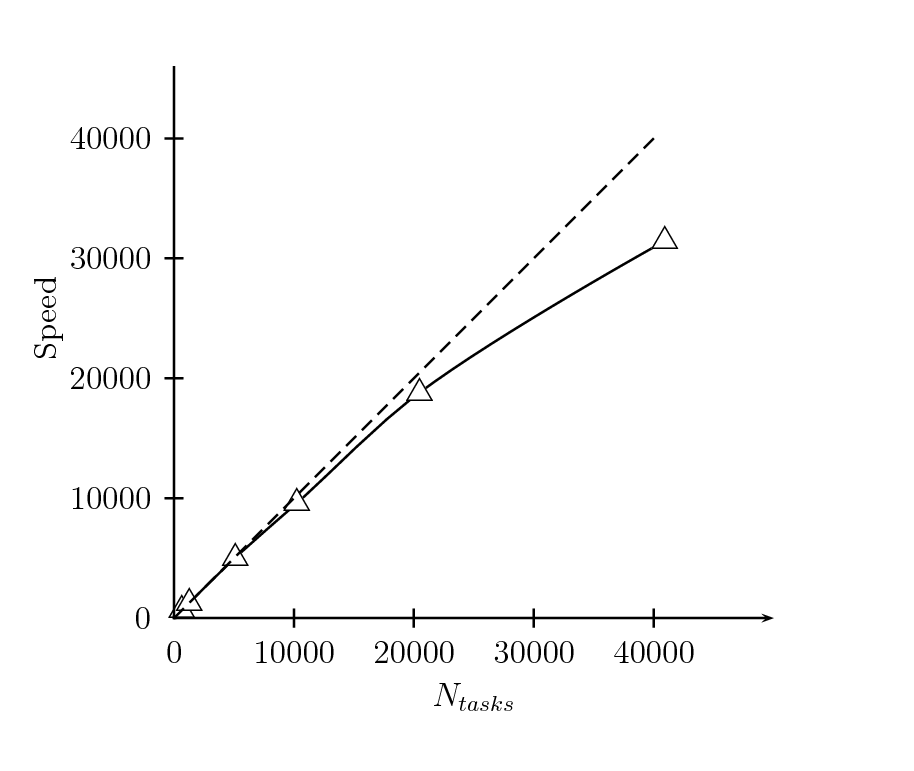
Another significant slowdown, of the order of one 60 minutes, was observed in runs with more that 5000 cores at the reading of the file config.in. Contrary to the BC data file this file is in binary format, the long input time was caused by the fact that in the initial algorithm each task opens the file config.in to read its share of configuration at the beginning of the calculation. The problem was solved by a new version of the configurations reading subroutine in which only a small group of tasks read the file config.in and transfers the data to the associates tasks via MPI communications. In this new version the reading time decrease to tens of seconds even when using 40,000 tasks.
 |