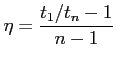Next: Second parallelism level with Up: Improving the parallelisation and Previous: Test results Contents
The second level parallelism (SLP) algorithm seeks to increase the
computation speed by employing more than one task to move one RW
configuration to its next state. As the computation time of a
configuration in CASINO scales with ![]() , with
, with ![]() , the
computation time per configuration for a system with
, the
computation time per configuration for a system with
![]() electrons could be more 100 times longer than a
for a system with
electrons could be more 100 times longer than a
for a system with
![]() electrons, which is the maximum
size reached by the current calculations. As byproducts SLP solves the
large size BC problem because it distributes the BC data among the
group of task that perform the computation for one configuration and
improves the load balance of the parallel computation because the
relative difference between the number of configurations on different
pools decreases with the pool size (for a calculation with a
fixed number of configurations per task or pool of tasks).
electrons, which is the maximum
size reached by the current calculations. As byproducts SLP solves the
large size BC problem because it distributes the BC data among the
group of task that perform the computation for one configuration and
improves the load balance of the parallel computation because the
relative difference between the number of configurations on different
pools decreases with the pool size (for a calculation with a
fixed number of configurations per task or pool of tasks).
As in the case of MPI-2S algorithm SLP divides the tasks in groups, named pools, of given size (typically 2 or 4). At start the program reads the BC and distribute them among the pool members similar to MPI-2S algorithm. The difference is that only one configuration is computed at a time by all the tasks belonging to a pool. One of the tasks, named ''pool head'', controls the computation and sends signals to the other tasks about the next step of the computation. In this manner the synchronisation problem of MPI-2S algorithm is removed and the pool's tasks can be used to compute in parallel more quantities beside the orbitals: sums that appear in the Jastrow factor, the potential energy and linear algebra operations needed for the Slater matrices.
We analyse the efficiency of SLP algorithm in the following way: in
the ideal case for a pool of size n the computation time of one
configuration would be ![]() . However the communication time
between tasks is not negligible and the work is not equally
distributed over the pool's tasks because there are computations done
only on the pool's head. We can measure the efficiency of a pool usage
with the following parameter:
. However the communication time
between tasks is not negligible and the work is not equally
distributed over the pool's tasks because there are computations done
only on the pool's head. We can measure the efficiency of a pool usage
with the following parameter:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
In Table ![[*]](crossref.png) we present the computation times for three
sections that are done in parallel over the pool: one particle orbitals (OPO),
Jastrow function, Ewald sum and also for the whole (DMC) section; the pool
sizes are
we present the computation times for three
sections that are done in parallel over the pool: one particle orbitals (OPO),
Jastrow function, Ewald sum and also for the whole (DMC) section; the pool
sizes are ![]() . The input file is identical to that used for shared
memory measurements, see Table . The efficiency
parameter shows that the best efficiency is obtained for pools of size 2
for OPO computation. In the case of pool of size 4 the OPO
computation is clearly more efficient on quadcore processor but the
other quantities have similar performance, though slightly better on quadcore.
We note also that the efficiency of the calculation OPO
increases for the larger system.
. The input file is identical to that used for shared
memory measurements, see Table . The efficiency
parameter shows that the best efficiency is obtained for pools of size 2
for OPO computation. In the case of pool of size 4 the OPO
computation is clearly more efficient on quadcore processor but the
other quantities have similar performance, though slightly better on quadcore.
We note also that the efficiency of the calculation OPO
increases for the larger system.
| ||||||||||||||||||||||||||||||||
The overall efficiency in DMC sector of the current implementation is
rather small as the computations of the Slater determinant and of the
associated matrices are done on the pool's head. The Slater
determinants are computed in two ways in CASINO: i) using LU
factorisation of the Slater matrix, which scales as ![]() , ii)
using an iterative relationship for the cofactor matrix
[9], which scale as
, ii)
using an iterative relationship for the cofactor matrix
[9], which scale as ![]() but is numerically
unstable. We have implemented a parallel computation over the pool
cores of this two subroutines for VMC calculations using Scalapack
subroutines. The timing results, Table , shows an
excellent scaling for the
but is numerically
unstable. We have implemented a parallel computation over the pool
cores of this two subroutines for VMC calculations using Scalapack
subroutines. The timing results, Table , shows an
excellent scaling for the ![]() algorithm but little improvement
or slight degradation for
algorithm but little improvement
or slight degradation for ![]() algorithm which in fact has a much
larger weight in the computation time ( in the last version of CASINO
LU computation of the Slater determinant is call by default every
100,000 time steps).
algorithm which in fact has a much
larger weight in the computation time ( in the last version of CASINO
LU computation of the Slater determinant is call by default every
100,000 time steps).