Next: Hybrid Parallelism in CABARET Up: Multi-core Data Parallelism Previous: Distributed Data Parallelism in Contents
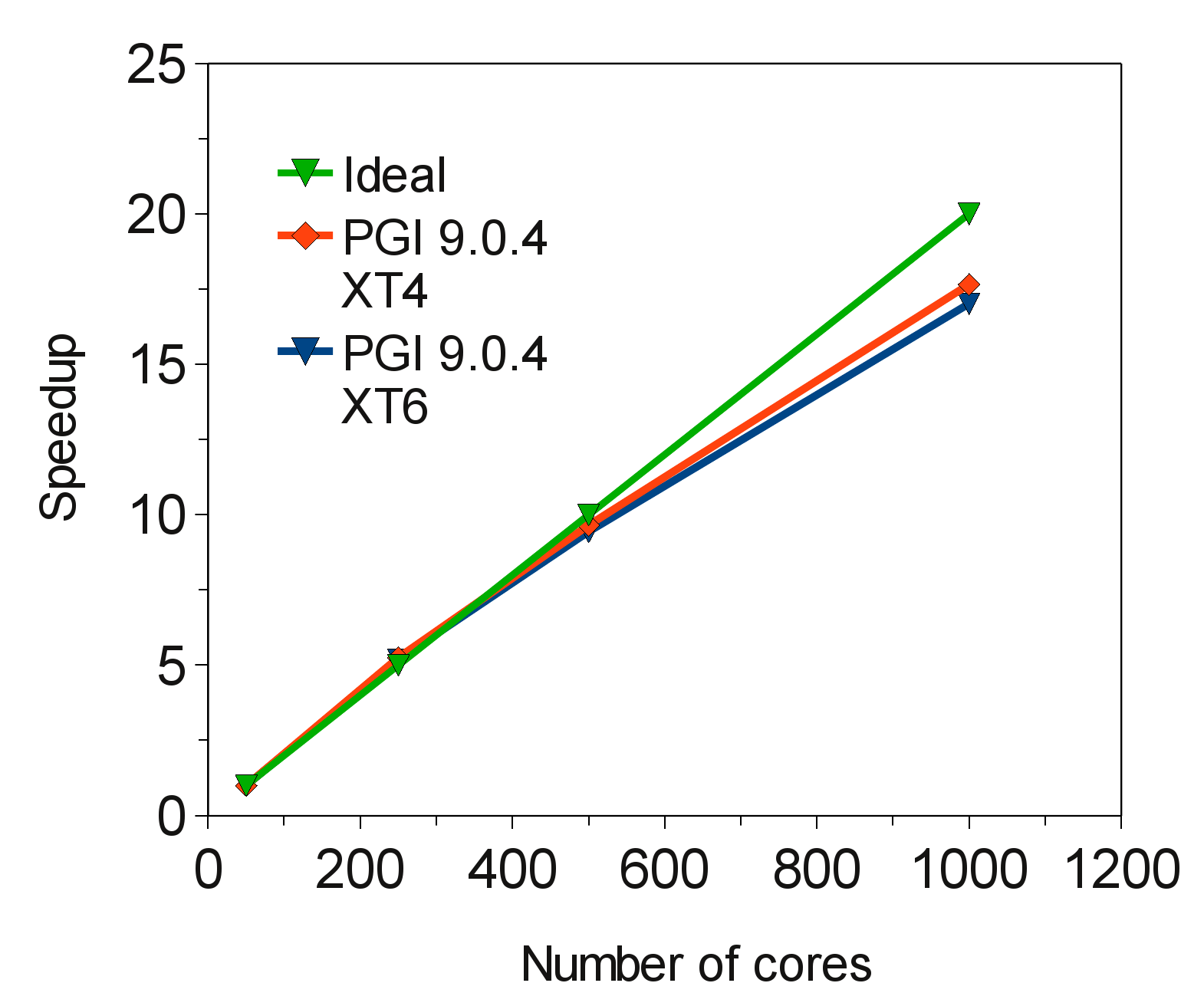
To demonstrate the initial performance of the MPI only CABARET on Phase 2b of HECToR, the scalability of the code to perform 276 time steps without any I/O involved is shown in Figure ![[*]](crossref.png) . The test case used here is a 3D backward facing step geometry and the boundary conditions are for laminar flow, with Reynolds number=5000 and Mach number=0.1. The grid is
. The test case used here is a 3D backward facing step geometry and the boundary conditions are for laminar flow, with Reynolds number=5000 and Mach number=0.1. The grid is
![]() hexahedral cells. The code was compiled with the PGI 9.0.4 Fortran 90 compiler.
hexahedral cells. The code was compiled with the PGI 9.0.4 Fortran 90 compiler.
Figure shows results for both Phase 2a (quad core) and Phase 2b (Seastar2+ interconnect) of HECToR. The interesting observation is that there is little performance degradation moving from quad core to 24 core nodes - even with the increased contention for inter-process bandwidth. In tests on both Phase 2a and Phase 2b the nodes were fully populated with the MPI tasks. In general we would expect that an increased amount of contention for interconnect use would occur due to the increased number of MPI tasks per node, but with this problem size this doesn't happen.
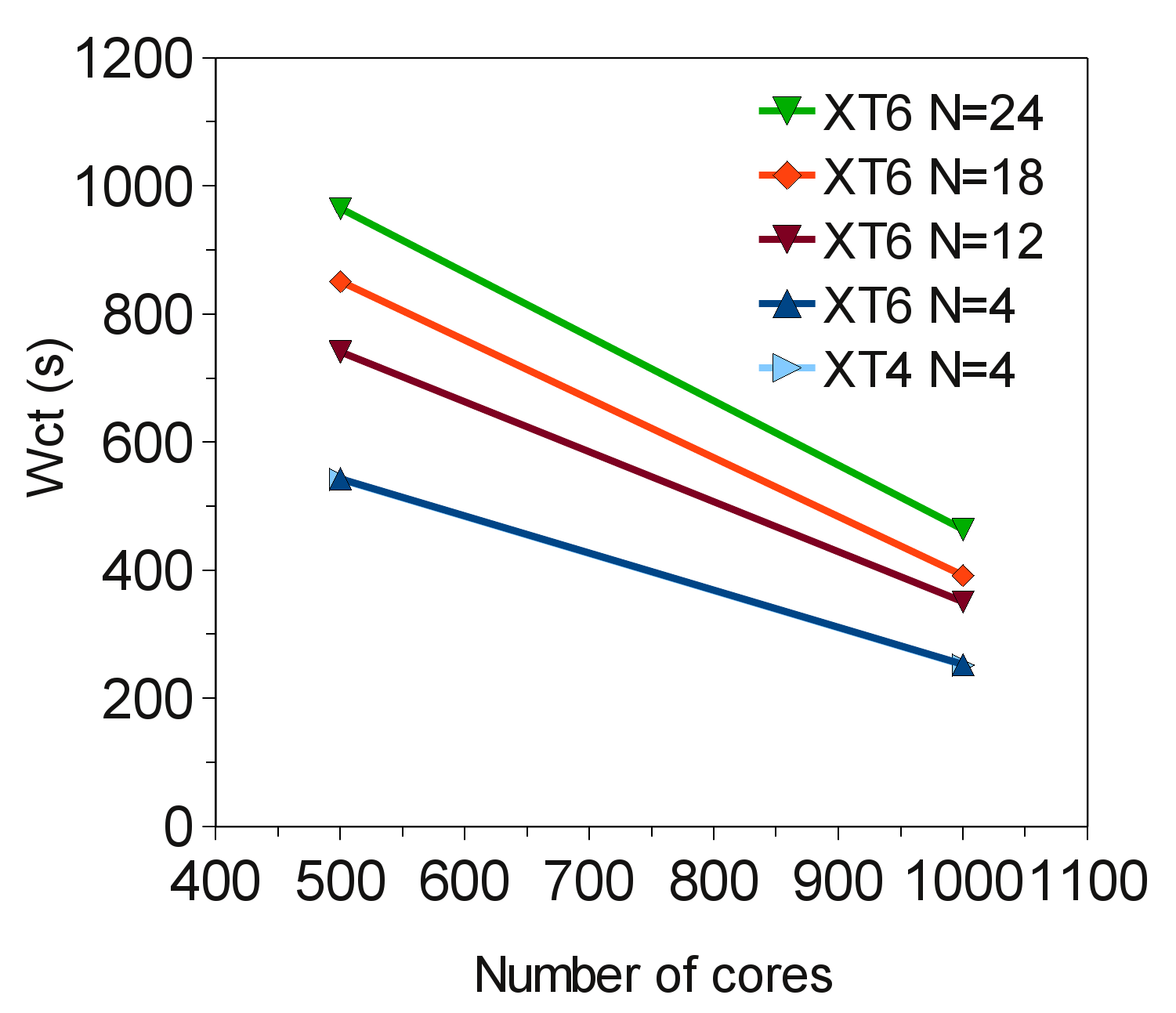
However, if we increase the size of the problem, very different behaviour is observed. When moving to a larger sized case of
![]() hexahedral cells, we can see in Figure that performance is clearly affected by moving from quad core to 24 core nodes. In Figure the positive performance is due to the size of the problem in question being accomodated by the available cache/interconnect arrangement.
hexahedral cells, we can see in Figure that performance is clearly affected by moving from quad core to 24 core nodes. In Figure the positive performance is due to the size of the problem in question being accomodated by the available cache/interconnect arrangement.
In Figure we see that by running the MPI only CABARET code on Phase 2b (XT6 with Seastar2+ interconnect) using 500 and 1000 cores, the wall clock time for performing 256 iterations does decrease for all cases, whether fully populating a node (24 cores) or maintaining the same MPI process per node ratio as in Phase 2a (XT4) (4 cores). However, it is clear that the 4 cores per node case takes around half the time of the 24 cores per node case. This behaviour is expected and is a typical observation of porting a pure MPI code to a multi-core architecture.
It is worthwhile to note that running the same test on the Phase 2b XE6 (24 core Opteron 6172 2.1GHz processors, arranged as two dual hex core sockets per node in a non uniform memory architecture with a Gemini interconnect), shows an improved performance of around 17% when populating with 12-24 cores per node, e.g. for 500 cores, the 24 core per node run takes 970s on Seastar2+, whereas this reduces to 805s with Gemini.
The key difference between the Phase 2b XT6 and the XE6 is the replacement of the Seastar2+ interconnect with the Gemini one. The Seastar2+ chip router has 6 links implementing a 3D-torus of processors with a point-to-point bandwidth of 9.6 GB/s. The Gemini interconnect has one third or less the latency of the SeaStar2+ interconnect and can deliver about 100 times the message throughput of the SeaStar2+ interconnect - something on the order of 2 million packets per core per second.
The Gemini interface is able to process huge numbers of small messages due to its higher injection rate in comparison to that of the SeaStar2+ interconnect. Therefore one would expect that with varying problem size, the Gemini interconnect would show considerable benefits over the SeaStar2+ interconnect for the MPI only version of CABARET.
Phil Ridley 2011-02-01