Next: Compiler comparison Up: Efficiency of Partitioning Methods Previous: Comparison of the Efficiency Contents
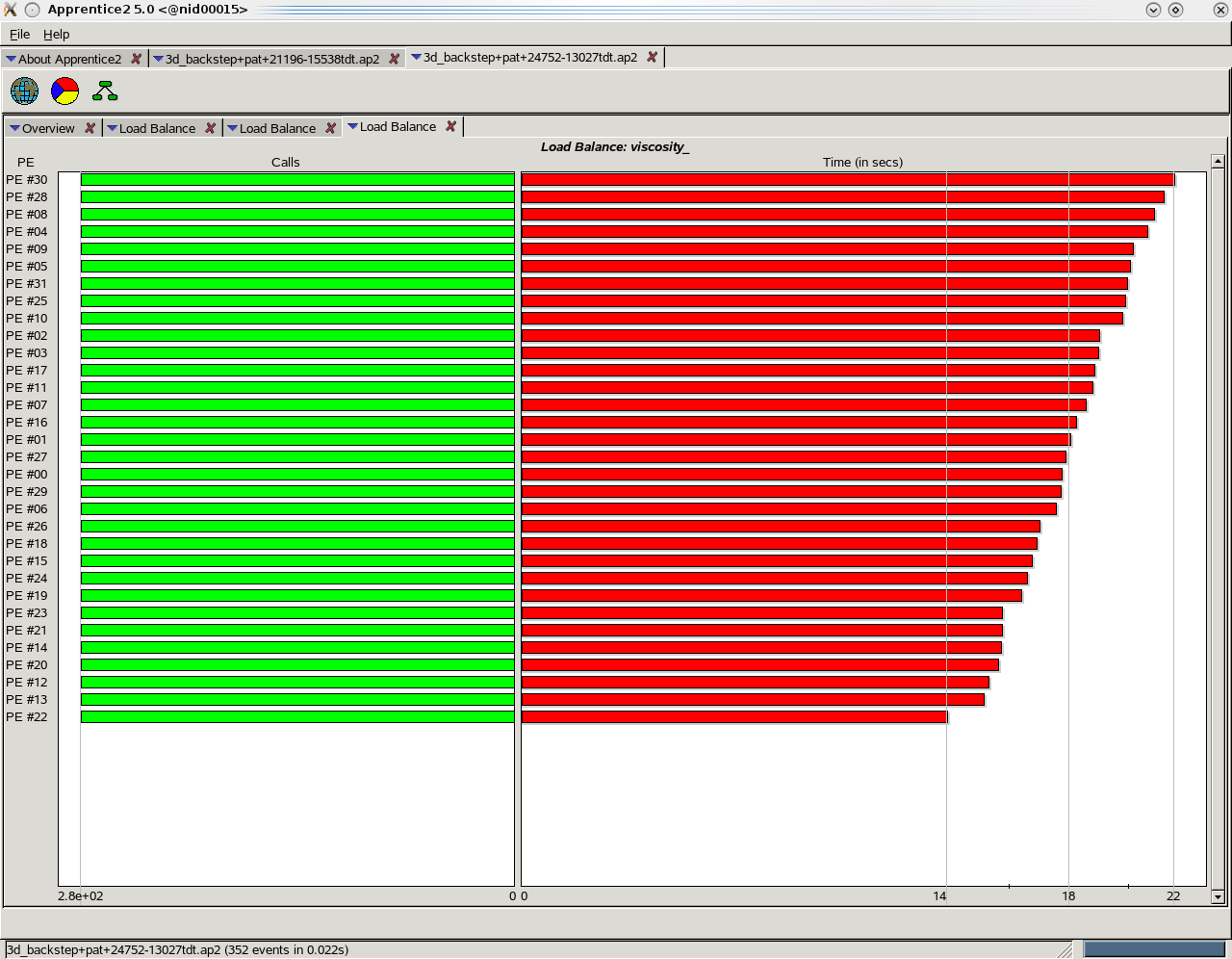
The main reason why partitioning the grid with Scotch enables CABARET to run slightly better is that for this particular problem, the partitioning produces more efficient load balancing and a balanced communication. The CrayPat profile in Figure ![[*]](crossref.png) demonstrates what often happens when using an unstructured partition for a structured geometry, e.g. Scotch or METIS. Here, there are 32 MPI processes (partitions) and process number 30 appears to have a third more work than process 22. The problem is caused by an uneven balance of cells within each partition along with the number of cells in each partition which contain boundary faces. The calculations which are dependent upon the boundary cells are VISCOSITY and BOUND. If there is an unfair distribution of the boundaries within the partitions then certain partitions may have an uneven load balance to cope with and this will in turn limit scalability.
demonstrates what often happens when using an unstructured partition for a structured geometry, e.g. Scotch or METIS. Here, there are 32 MPI processes (partitions) and process number 30 appears to have a third more work than process 22. The problem is caused by an uneven balance of cells within each partition along with the number of cells in each partition which contain boundary faces. The calculations which are dependent upon the boundary cells are VISCOSITY and BOUND. If there is an unfair distribution of the boundaries within the partitions then certain partitions may have an uneven load balance to cope with and this will in turn limit scalability.
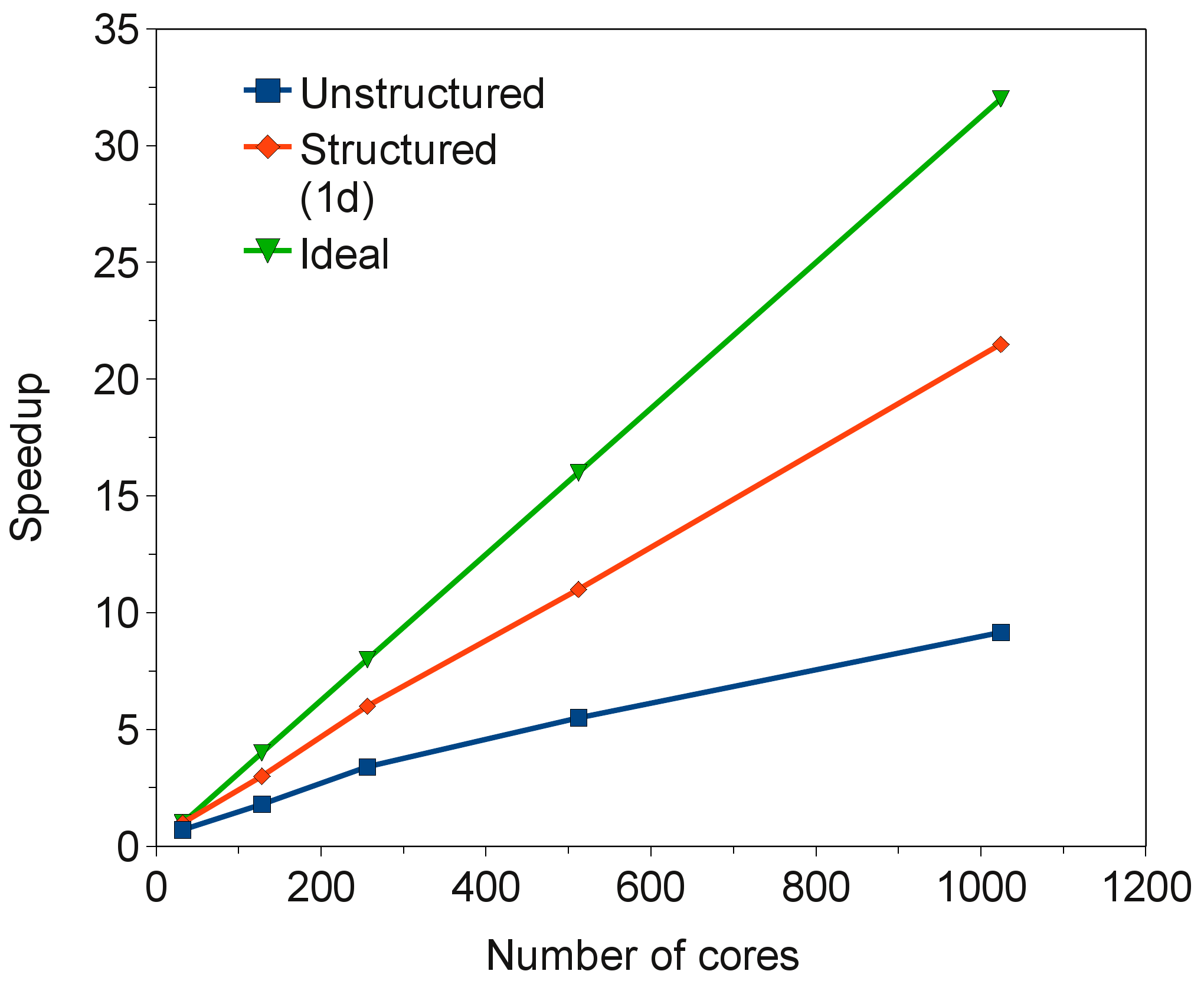
For a structured geometry such as the 3D backward facing step, it is more efficient to use a structured partitioning approach based on cutting along the cartesian plane(s). This approach can be used to ensure that an equally distributed amount of work for each MPI process is achieved and inter process communication is minimised. Referring back to Figure , for a structured one dimensional partition, we may simply allocate the required number of partitions by slicing the geometry by planes along the x axis. The spacing of these planes ensures that there is an even distribution of both non-boundary and boundary cells (i.e. the number of cell faces that are on a boundary, which is from 0-6 for a hexahedral cell). It's worthwhile to note that since there is a finite volume aspect to the CABARET algorithm, we have to be careful when determining neighbouring partitions. Sides alone are not enough to distinguish neighbours since partitions can be connected by a single apex. However, this situation cannot happen with a one or two dimensional data decomposition, but is possible with three dimensional and unstructured ones.
To demonstrate the performance of the MPI only CABARET for structured and unstructured partitions, the scalability of the code was measured when performing 276 time steps (without any I/O) was measured. The test case used here is a 3D backward facing step geometry and the boundary conditions are for laminar flow, with Reynolds number=5000 and Mach number=0.1. The grid size is
![]() hexahedral cells. This run was performed on Phase 2a of HECToR (with each node a quad core 2.3GHz Opteron processor with 8GB of RAM) using the PGI 10.8.0 Fortran90 compiler. Figure shows that there is more than a 2 times speedup when using a strutured data decomposition which gives good load balancing.
hexahedral cells. This run was performed on Phase 2a of HECToR (with each node a quad core 2.3GHz Opteron processor with 8GB of RAM) using the PGI 10.8.0 Fortran90 compiler. Figure shows that there is more than a 2 times speedup when using a strutured data decomposition which gives good load balancing.