Next: Data decomposition Up: CABARET Implementation for HECToR Previous: Output Data Contents
For the computation, we can summarise that CABARET involves calculations based on variables which either relate to the flux type, cell sides (SIDE) or the conservative type cell based (CELL). Additionally there is also the grid point based variables (APEX) which are calculated from the neighbouring CELL values.
In terms of implementing data parallelism within the code, the CABARET algorithm requires knowledge of only the nearest neighbouring cells, so we need to store a set of halo values of CELL, SIDE and APEX on each process and then update them at appropriate points in the calculation. This is in addition to the local to global address mapping information regarding the computational grid. However, this remains static throughout the calculation and so no communication is required for this data.
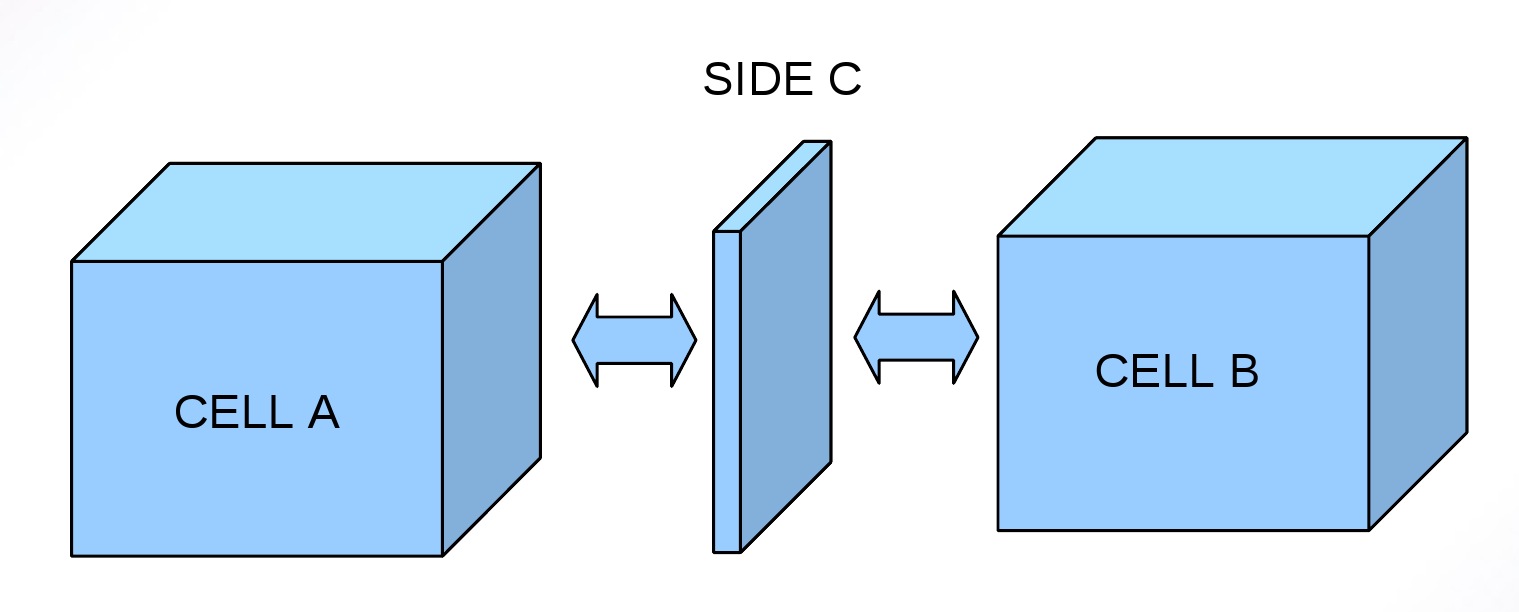
The values in the APEX array require no communication since they can always be determined from the halo CELL values and local process CELL values. Whenever there is an update to the flux type i.e. SIDE values we shall need to communicate updates to the halo CELL values on the other neighbouring processes. This is because each SIDE has two associated CELLs as shown in Figure ![[*]](crossref.png) and both of these may not necessarily exist as halo CELLs on each process.
and both of these may not necessarily exist as halo CELLs on each process.
This aspect of the computation means that we need updates for halo values of SIDE based calculations to be communicated both before PHASE2 and after BOUND for each time step of the CABARET calculation. The actual implementation is described below and this includes two nearest neighbour based communications which involve updating both the conservative and flux type (CELL and SIDE) variables.
To summarise the computational process, which is repeated at each time step. This includes two nearest neighbour based communications and one global reduction. This was implemented within the CABARET code with MPI, using a local (indirect) referencing system for the APEX, SIDE, and CELL data for each MPI process and non-blocking MPI calls to update halo data at each time step. When output data is required, (for restarts and Tecplot) data is sent to the master process for writing to two separate files for post processing.
Phil Ridley 2011-02-01